# Goals of the PR
The PR introduces **no changes to functionality**, apart from improved
input validation here and there. The main goals are to reduce some
complexity of the code, to improve types and IDE completions, and to
extend documentation and block comments where appropriate. Because of
the change to the trainer interfaces, many files are affected (more
details below), but still the overall changes are "small" in a certain
sense.
## Major Change 1 - BatchProtocol
**TL;DR:** One can now annotate which fields the batch is expected to
have on input params and which fields a returned batch has. Should be
useful for reading the code. getting meaningful IDE support, and
catching bugs with mypy. This annotation strategy will continue to work
if Batch is replaced by TensorDict or by something else.
**In more detail:** Batch itself has no fields and using it for
annotations is of limited informational power. Batches with fields are
not separate classes but instead instances of Batch directly, so there
is no type that could be used for annotation. Fortunately, python
`Protocol` is here for the rescue. With these changes we can now do
things like
```python
class ActionBatchProtocol(BatchProtocol):
logits: Sequence[Union[tuple, torch.Tensor]]
dist: torch.distributions.Distribution
act: torch.Tensor
state: Optional[torch.Tensor]
class RolloutBatchProtocol(BatchProtocol):
obs: torch.Tensor
obs_next: torch.Tensor
info: Dict[str, Any]
rew: torch.Tensor
terminated: torch.Tensor
truncated: torch.Tensor
class PGPolicy(BasePolicy):
...
def forward(
self,
batch: RolloutBatchProtocol,
state: Optional[Union[dict, Batch, np.ndarray]] = None,
**kwargs: Any,
) -> ActionBatchProtocol:
```
The IDE and mypy are now very helpful in finding errors and in
auto-completion, whereas before the tools couldn't assist in that at
all.
## Major Change 2 - remove duplication in trainer package
**TL;DR:** There was a lot of duplication between `BaseTrainer` and its
subclasses. Even worse, it was almost-duplication. There was also
interface fragmentation through things like `onpolicy_trainer`. Now this
duplication is gone and all downstream code was adjusted.
**In more detail:** Since this change affects a lot of code, I would
like to explain why I thought it to be necessary.
1. The subclasses of `BaseTrainer` just duplicated docstrings and
constructors. What's worse, they changed the order of args there, even
turning some kwargs of BaseTrainer into args. They also had the arg
`learning_type` which was passed as kwarg to the base class and was
unused there. This made things difficult to maintain, and in fact some
errors were already present in the duplicated docstrings.
2. The "functions" a la `onpolicy_trainer`, which just called the
`OnpolicyTrainer.run`, not only introduced interface fragmentation but
also completely obfuscated the docstring and interfaces. They themselves
had no dosctring and the interface was just `*args, **kwargs`, which
makes it impossible to understand what they do and which things can be
passed without reading their implementation, then reading the docstring
of the associated class, etc. Needless to say, mypy and IDEs provide no
support with such functions. Nevertheless, they were used everywhere in
the code-base. I didn't find the sacrifices in clarity and complexity
justified just for the sake of not having to write `.run()` after
instantiating a trainer.
3. The trainers are all very similar to each other. As for my
application I needed a new trainer, I wanted to understand their
structure. The similarity, however, was hard to discover since they were
all in separate modules and there was so much duplication. I kept
staring at the constructors for a while until I figured out that
essentially no changes to the superclass were introduced. Now they are
all in the same module and the similarities/differences between them are
much easier to grasp (in my opinion)
4. Because of (1), I had to manually change and check a lot of code,
which was very tedious and boring. This kind of work won't be necessary
in the future, since now IDEs can be used for changing signatures,
renaming args and kwargs, changing class names and so on.
I have some more reasons, but maybe the above ones are convincing
enough.
## Minor changes: improved input validation and types
I added input validation for things like `state` and `action_scaling`
(which only makes sense for continuous envs). After adding this, some
tests failed to pass this validation. There I added
`action_scaling=isinstance(env.action_space, Box)`, after which tests
were green. I don't know why the tests were green before, since action
scaling doesn't make sense for discrete actions. I guess some aspect was
not tested and didn't crash.
I also added Literal in some places, in particular for
`action_bound_method`. Now it is no longer allowed to pass an empty
string, instead one should pass `None`. Also here there is input
validation with clear error messages.
@Trinkle23897 The functional tests are green. I didn't want to fix the
formatting, since it will change in the next PR that will solve #914
anyway. I also found a whole bunch of code in `docs/_static`, which I
just deleted (shouldn't it be copied from the sources during docs build
instead of committed?). I also haven't adjusted the documentation yet,
which atm still mentions the trainers of the type
`onpolicy_trainer(...)` instead of `OnpolicyTrainer(...).run()`
## Breaking Changes
The adjustments to the trainer package introduce breaking changes as
duplicated interfaces are deleted. However, it should be very easy for
users to adjust to them
---------
Co-authored-by: Michael Panchenko <m.panchenko@appliedai.de>
Atari Environment
EnvPool
We highly recommend using envpool to run the following experiments. To install, in a linux machine, type:
pip install envpool
After that, atari_wrapper will automatically switch to envpool's Atari env. EnvPool's implementation is much faster (about 2~3x faster for pure execution speed, 1.5x for overall RL training pipeline) than python vectorized env implementation, and it's behavior is consistent to that approach (OpenAI wrapper), which will describe below.
For more information, please refer to EnvPool's GitHub, Docs, and 3rd-party report.
ALE-py
The sample speed is ~3000 env step per second (~12000 Atari frame per second in fact since we use frame_stack=4) under the normal mode (use a CNN policy and a collector, also storing data into the buffer).
The env wrapper is a crucial thing. Without wrappers, the agent cannot perform well enough on Atari games. Many existing RL codebases use OpenAI wrapper, but it is not the original DeepMind version (related issue). Dopamine has a different wrapper but unfortunately it cannot work very well in our codebase.
DQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters | time cost |
|---|---|---|---|---|
| PongNoFrameskip-v4 | 20 | 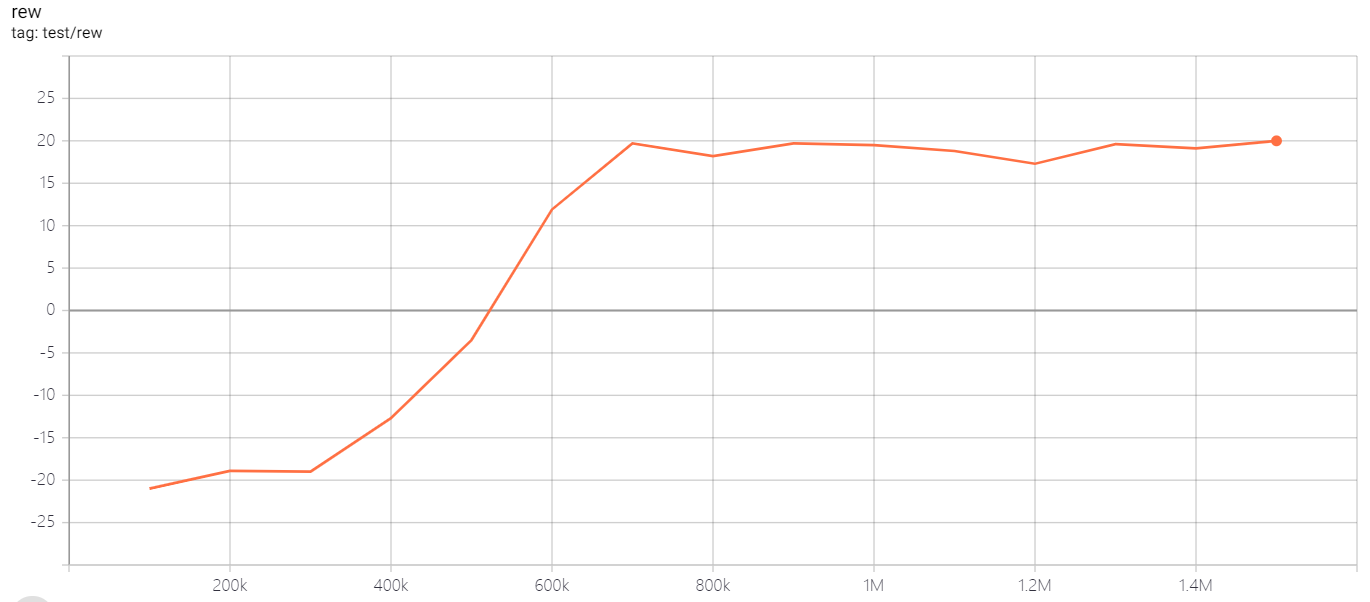 |
python3 atari_dqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
~30 min (~15 epoch) |
| BreakoutNoFrameskip-v4 | 316 | 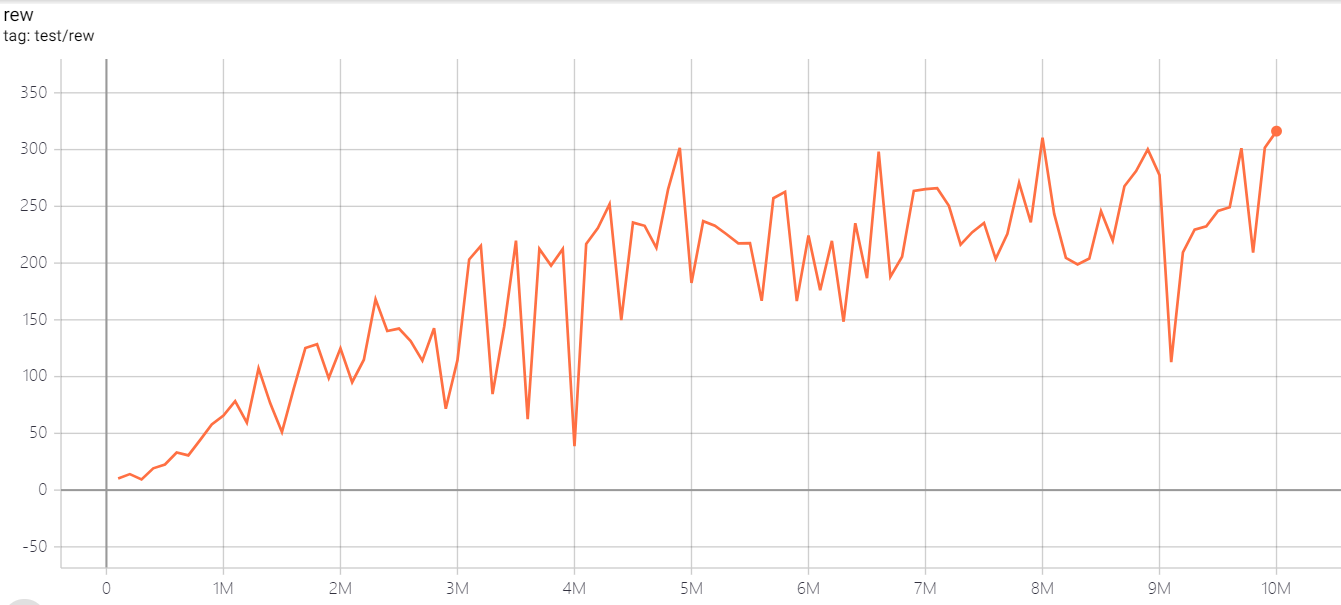 |
python3 atari_dqn.py --task "BreakoutNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| EnduroNoFrameskip-v4 | 670 | 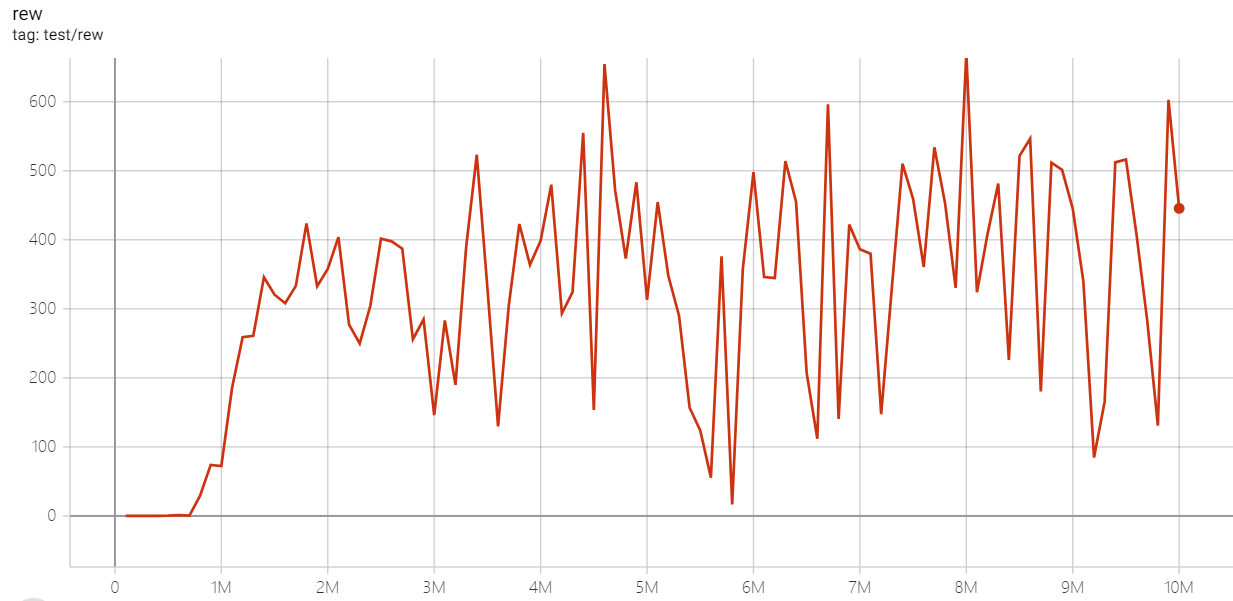 |
python3 atari_dqn.py --task "EnduroNoFrameskip-v4 " --test-num 100 |
3~4h (100 epoch) |
| QbertNoFrameskip-v4 | 7307 | 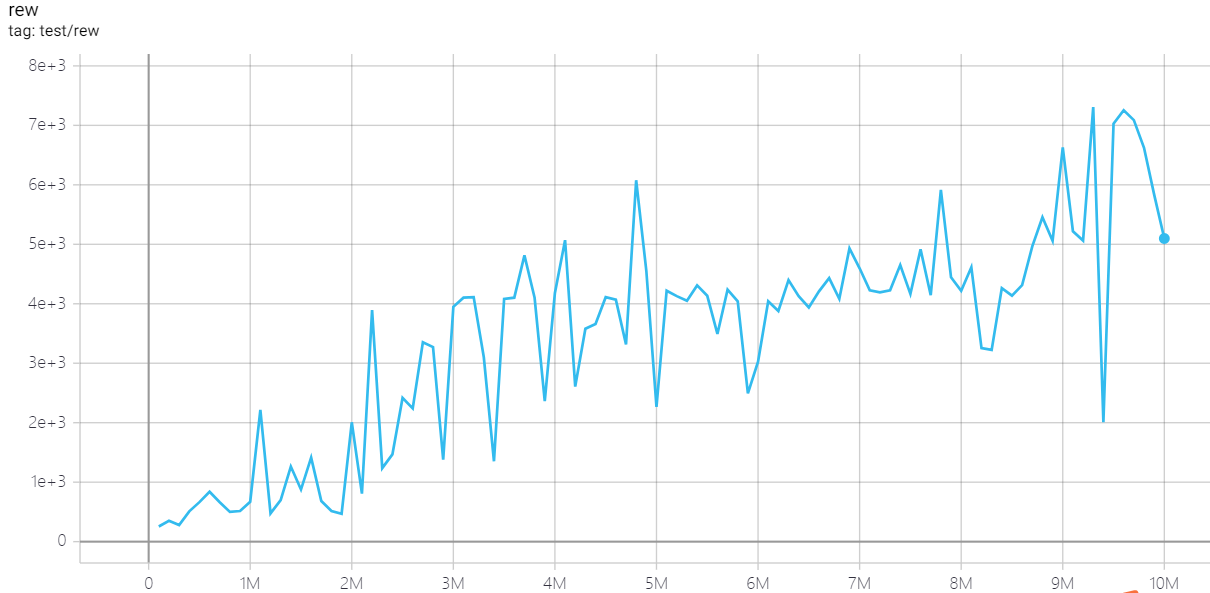 |
python3 atari_dqn.py --task "QbertNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| MsPacmanNoFrameskip-v4 | 2107 | 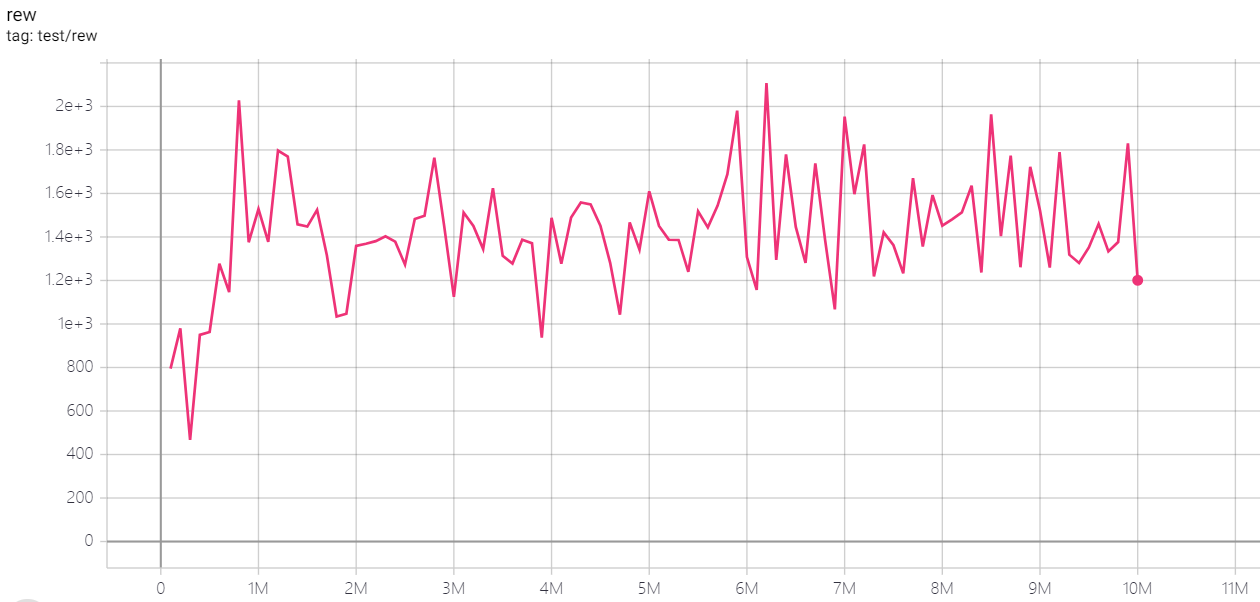 |
python3 atari_dqn.py --task "MsPacmanNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| SeaquestNoFrameskip-v4 | 2088 | 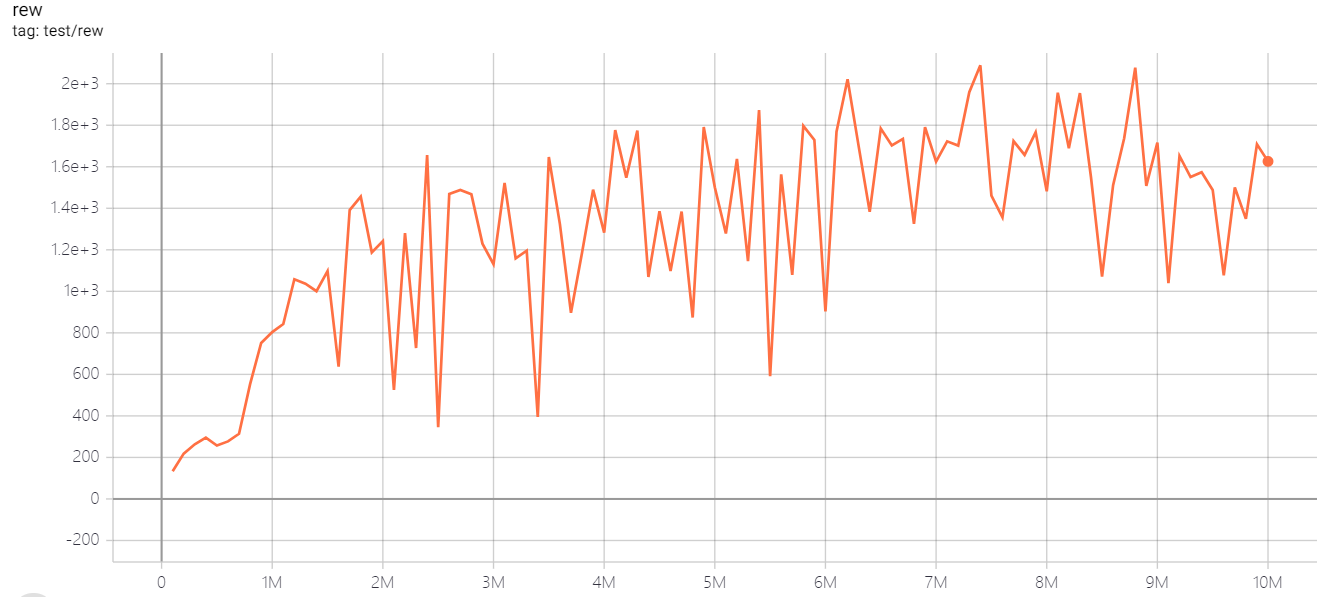 |
python3 atari_dqn.py --task "SeaquestNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| SpaceInvadersNoFrameskip-v4 | 812.2 |  |
python3 atari_dqn.py --task "SpaceInvadersNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
Note: The eps_train_final and eps_test in the original DQN paper is 0.1 and 0.01, but some works found that smaller eps helps improve the performance. Also, a large batchsize (say 64 instead of 32) will help faster convergence but will slow down the training speed.
We haven't tuned this result to the best, so have fun with playing these hyperparameters!
C51 (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20 |  |
python3 atari_c51.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 536.6 |  |
python3 atari_c51.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1032 |  |
python3 atari_c51.py --task "EnduroNoFrameskip-v4 " |
| QbertNoFrameskip-v4 | 16245 |  |
python3 atari_c51.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3133 |  |
python3 atari_c51.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 6226 |  |
python3 atari_c51.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 988.5 |  |
python3 atari_c51.py --task "SpaceInvadersNoFrameskip-v4" |
Note: The selection of n_step is based on Figure 6 in the Rainbow paper.
QRDQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20 | 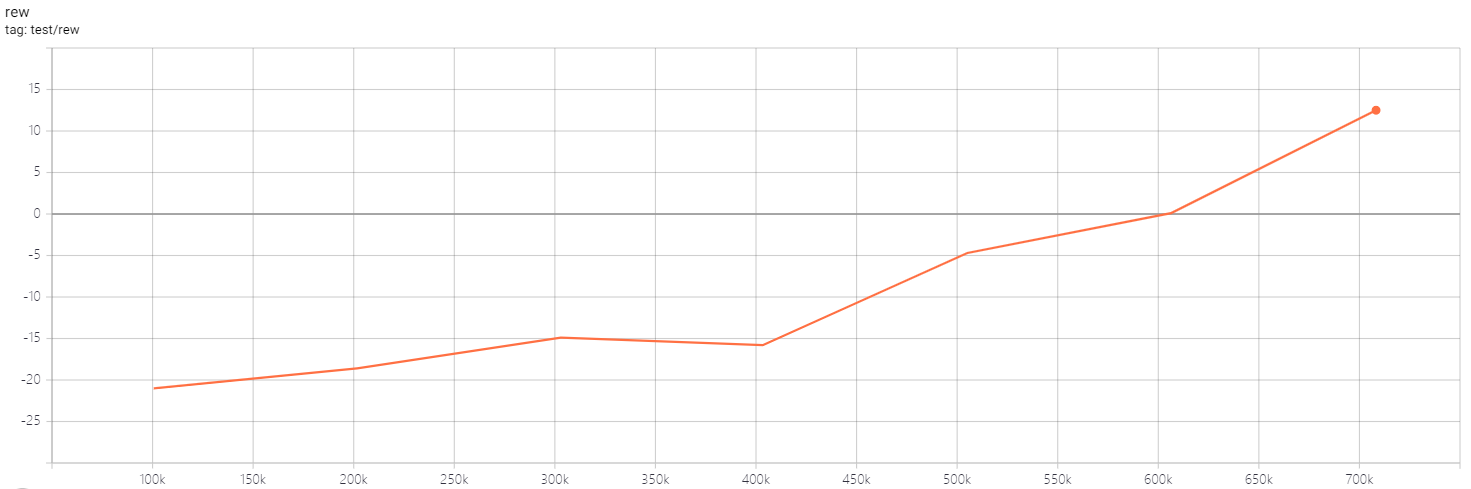 |
python3 atari_qrdqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 409.2 | 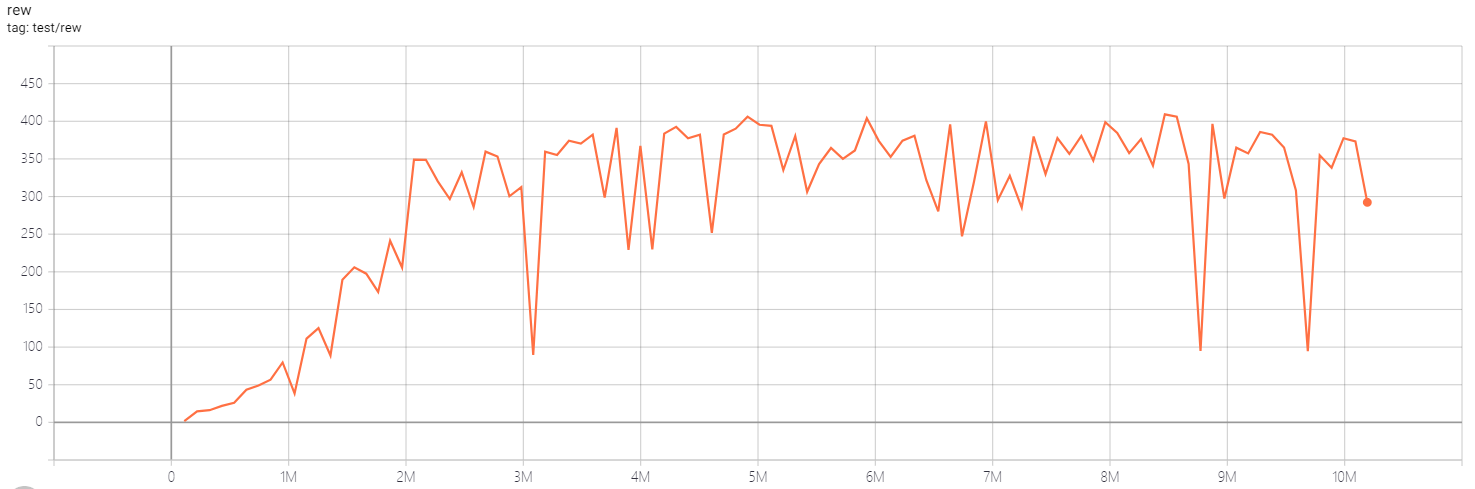 |
python3 atari_qrdqn.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1055.9 | 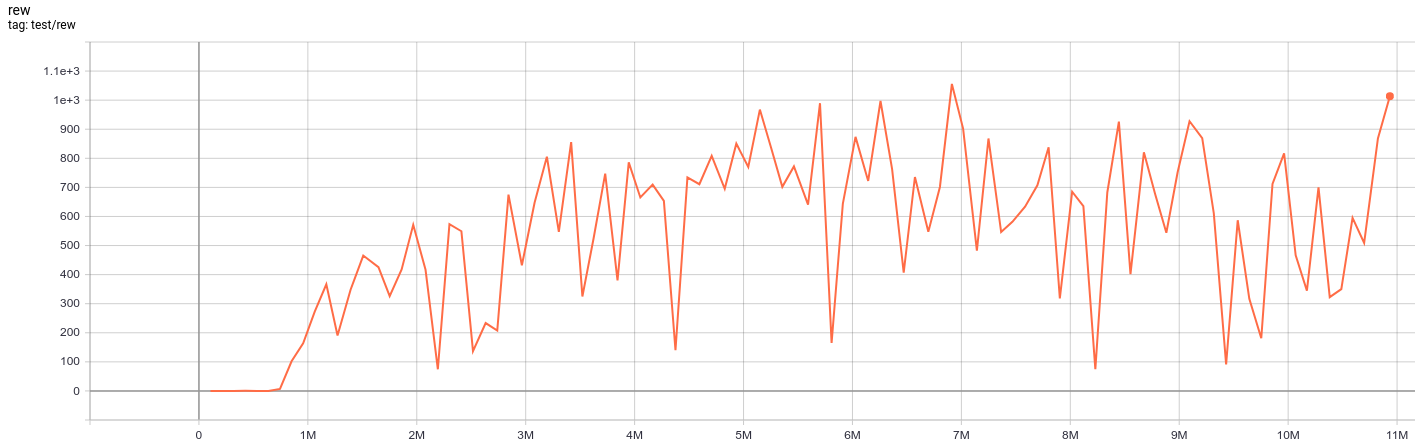 |
python3 atari_qrdqn.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 14990 | 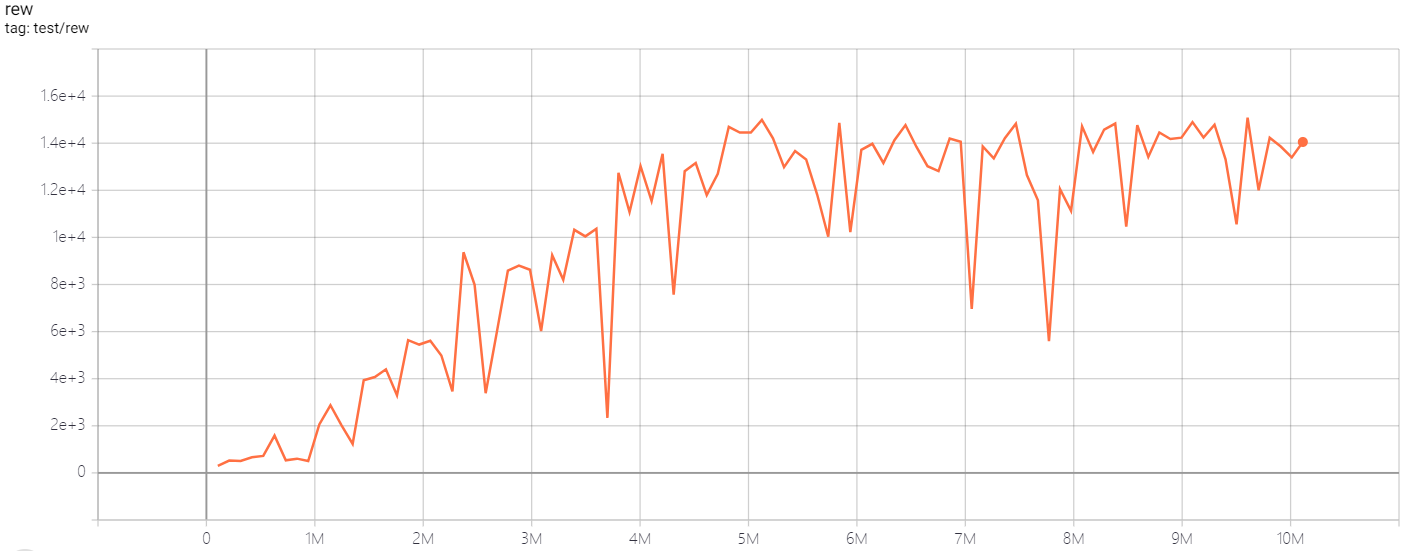 |
python3 atari_qrdqn.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2886 |  |
python3 atari_qrdqn.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 5676 | 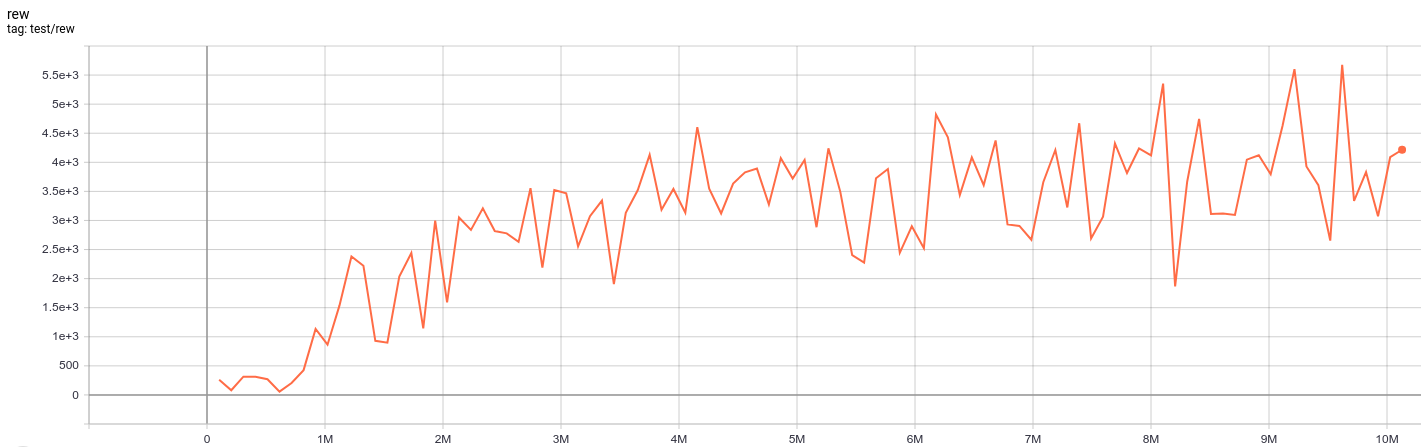 |
python3 atari_qrdqn.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 938 |  |
python3 atari_qrdqn.py --task "SpaceInvadersNoFrameskip-v4" |
IQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.3 |  |
python3 atari_iqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 496.7 | 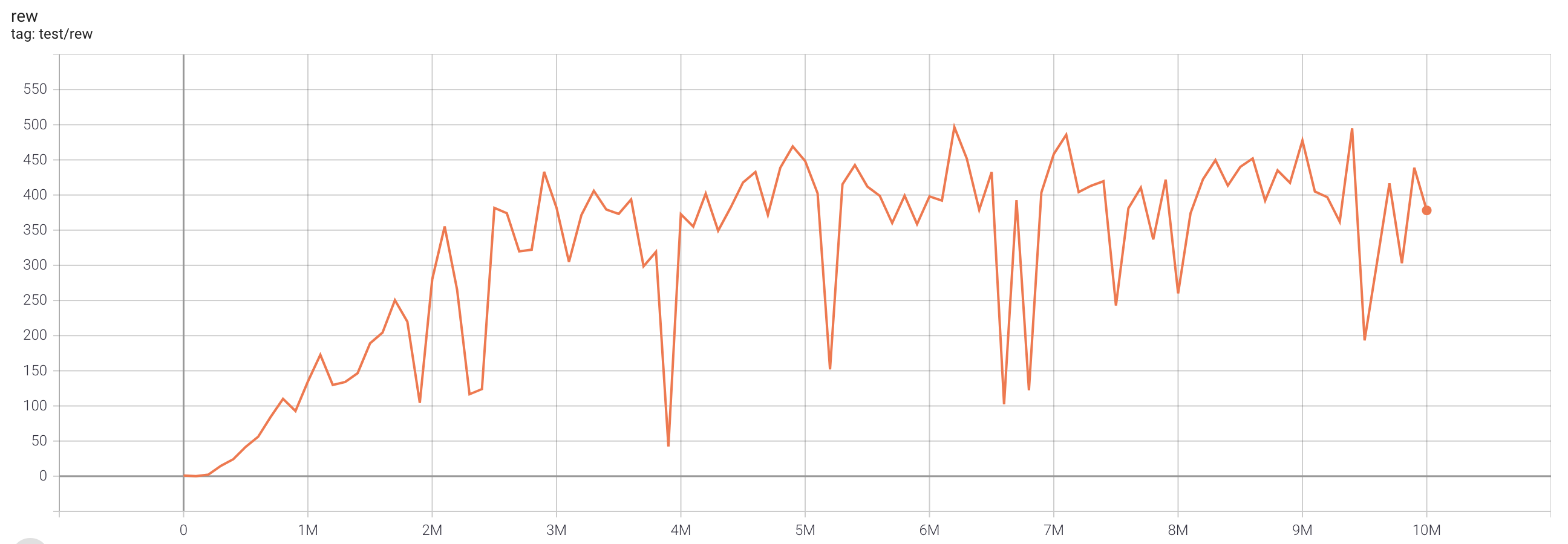 |
python3 atari_iqn.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1545 | 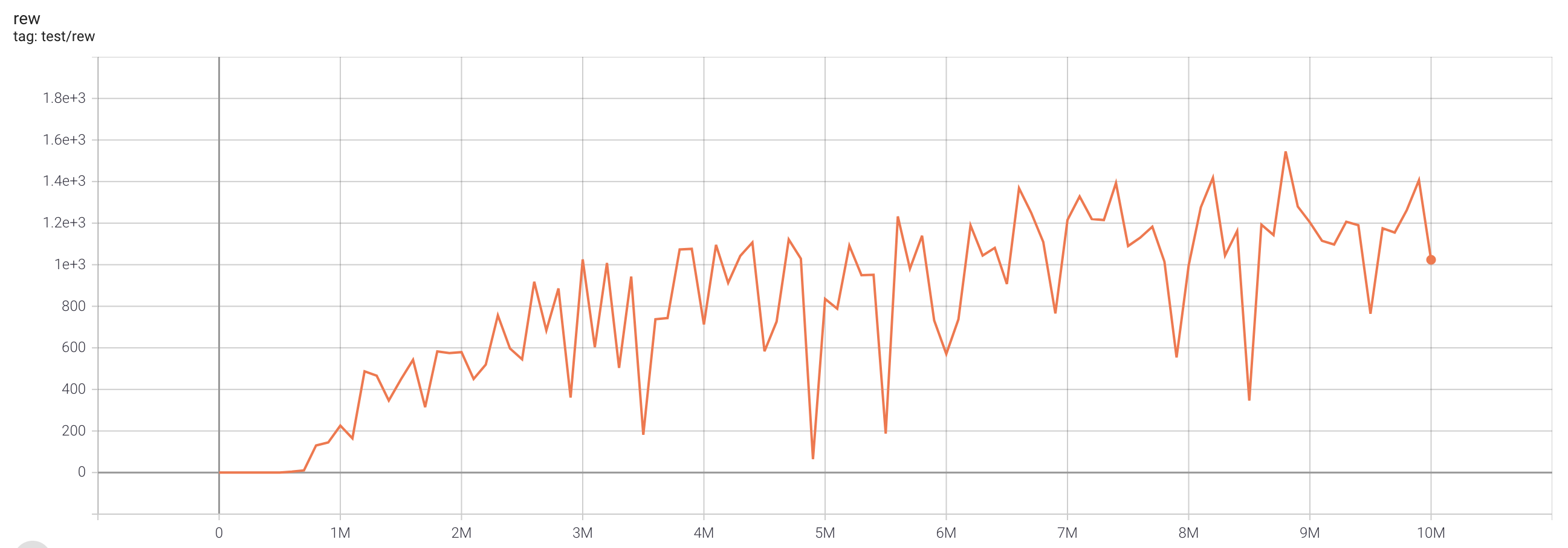 |
python3 atari_iqn.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 15342.5 |  |
python3 atari_iqn.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2915 |  |
python3 atari_iqn.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 4874 | 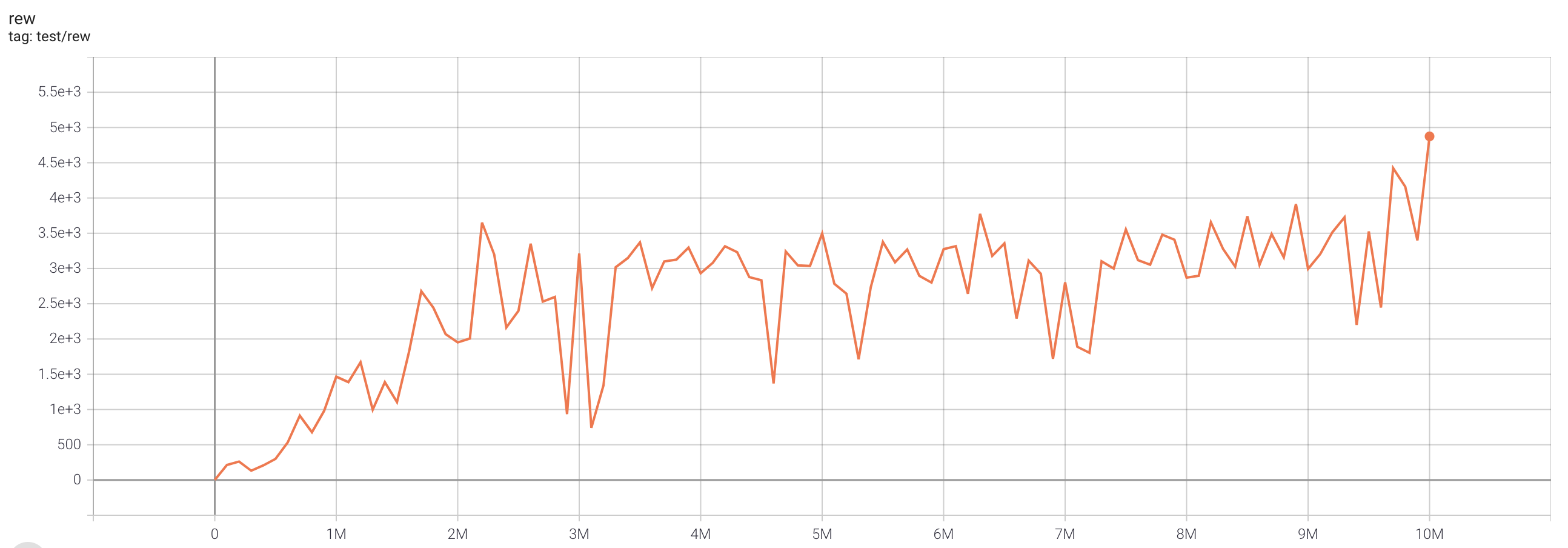 |
python3 atari_iqn.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 1498.5 | 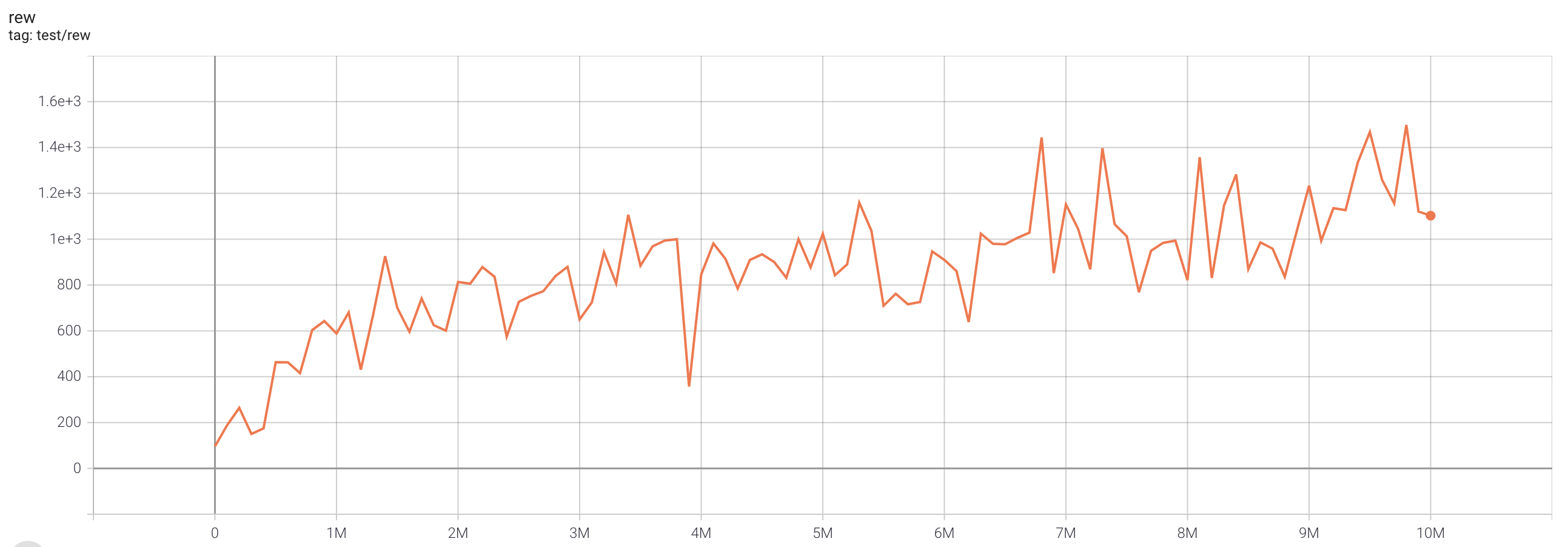 |
python3 atari_iqn.py --task "SpaceInvadersNoFrameskip-v4" |
FQF (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.7 | 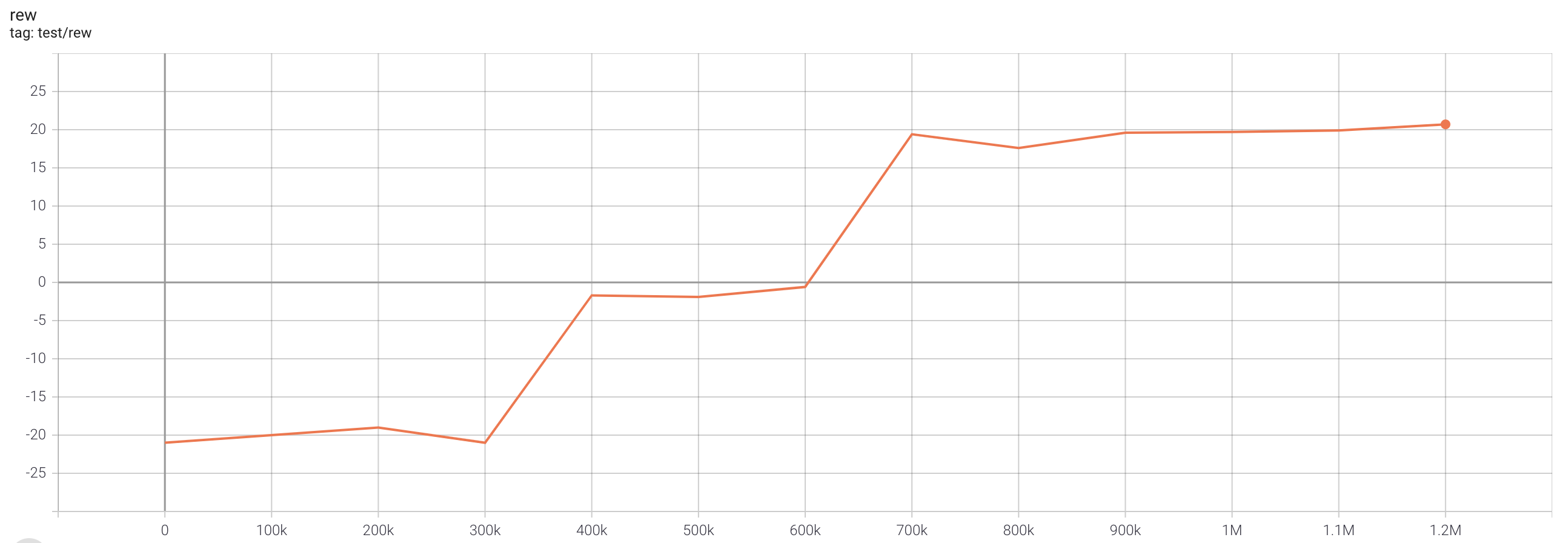 |
python3 atari_fqf.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 517.3 | 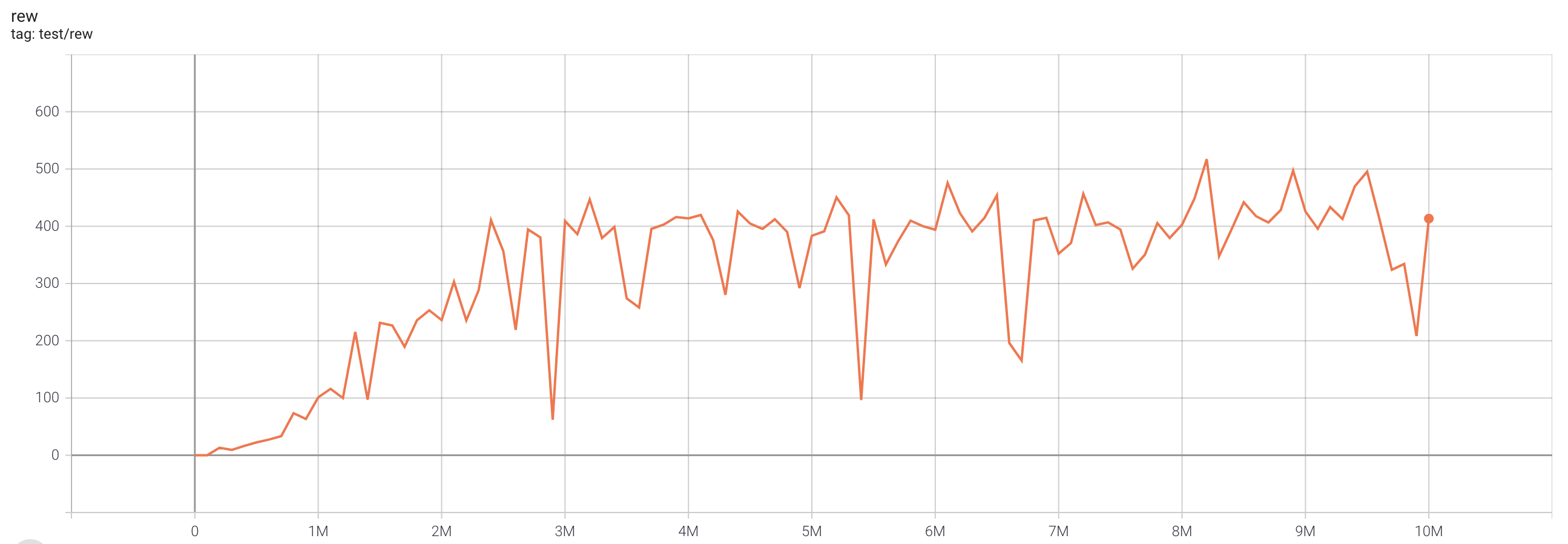 |
python3 atari_fqf.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 2240.5 | 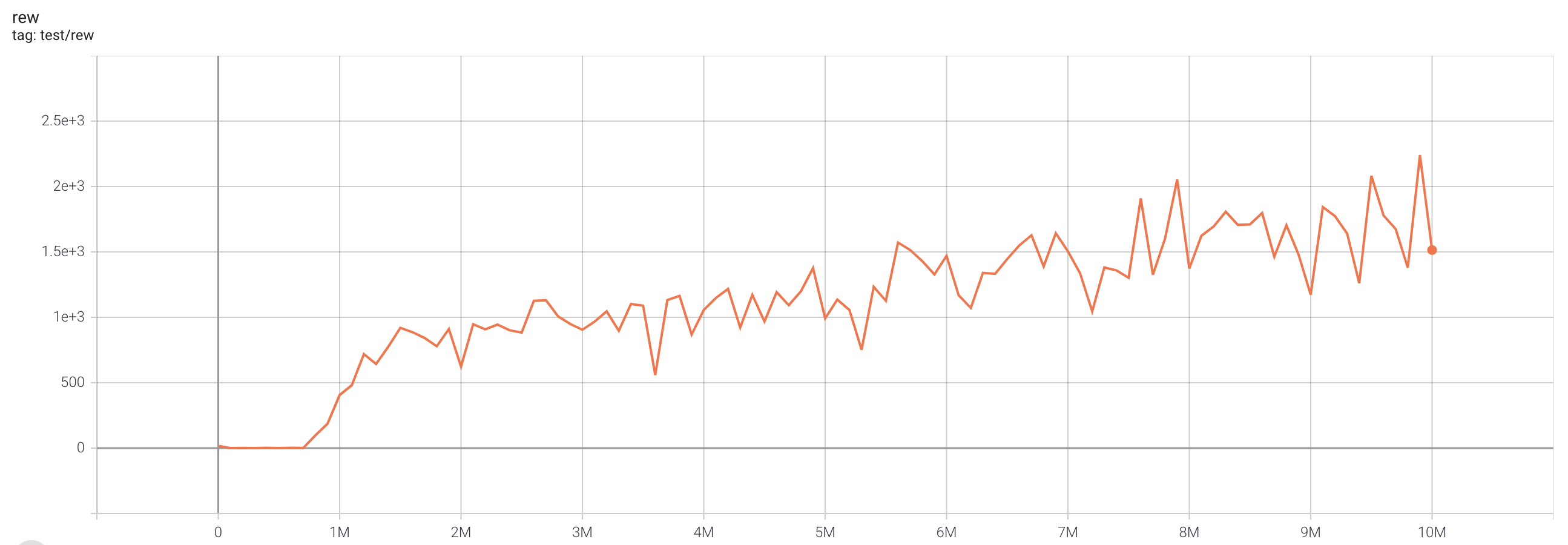 |
python3 atari_fqf.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 16172.5 | 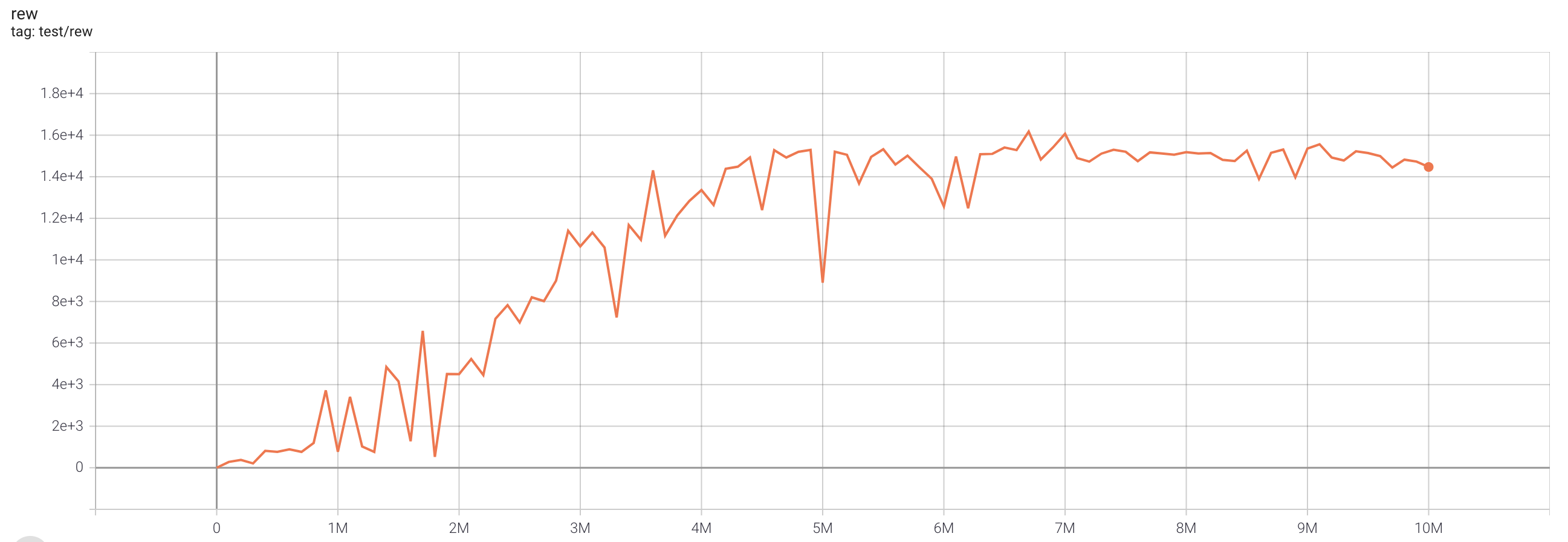 |
python3 atari_fqf.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2429 |  |
python3 atari_fqf.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 10775 | 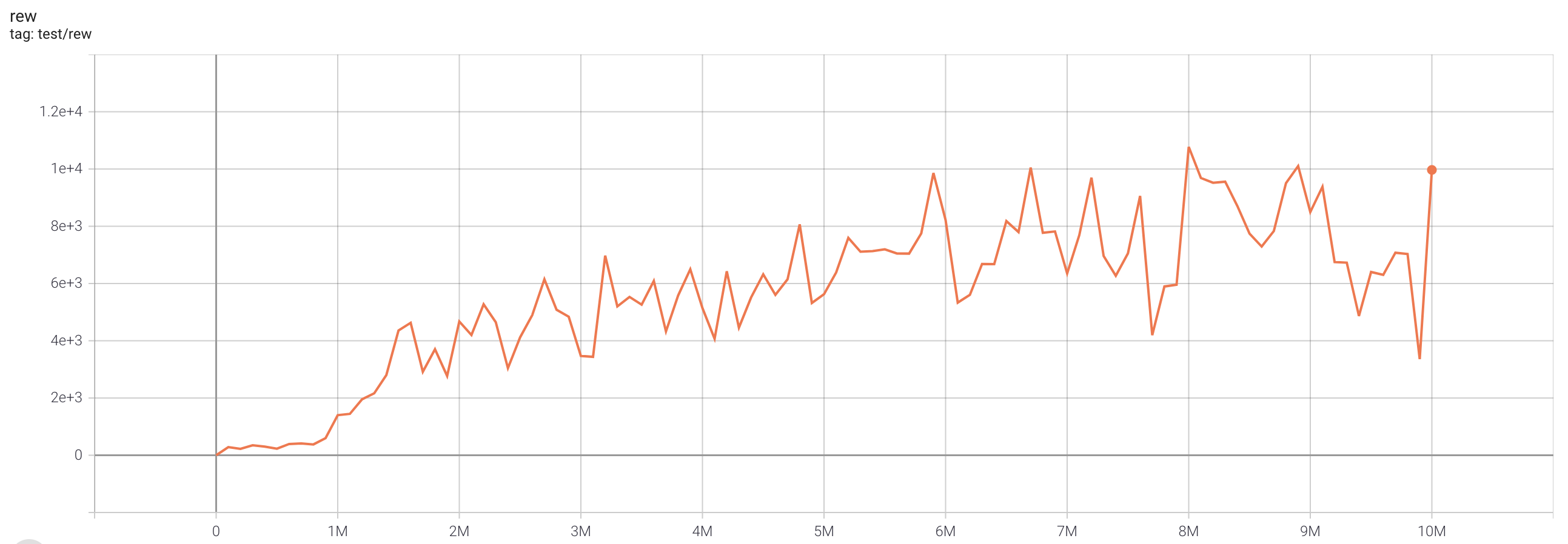 |
python3 atari_fqf.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 2482 |  |
python3 atari_fqf.py --task "SpaceInvadersNoFrameskip-v4" |
Rainbow (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 21 |  |
python3 atari_rainbow.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 684.6 | 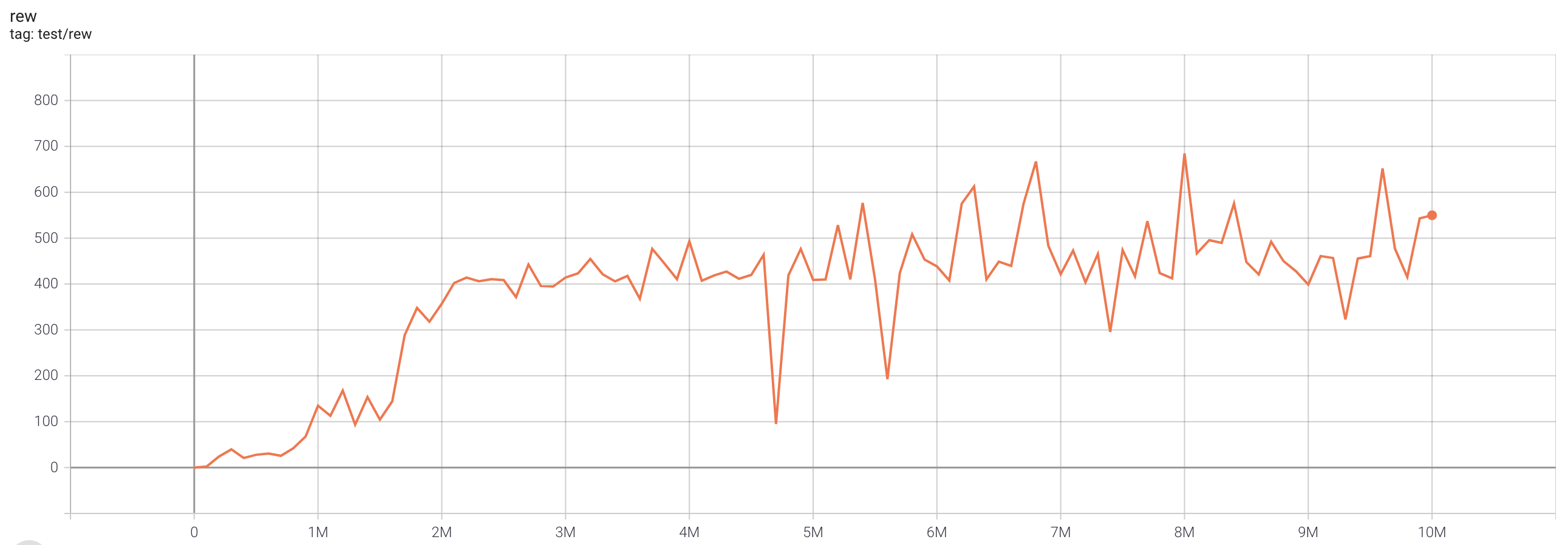 |
python3 atari_rainbow.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1625.9 | 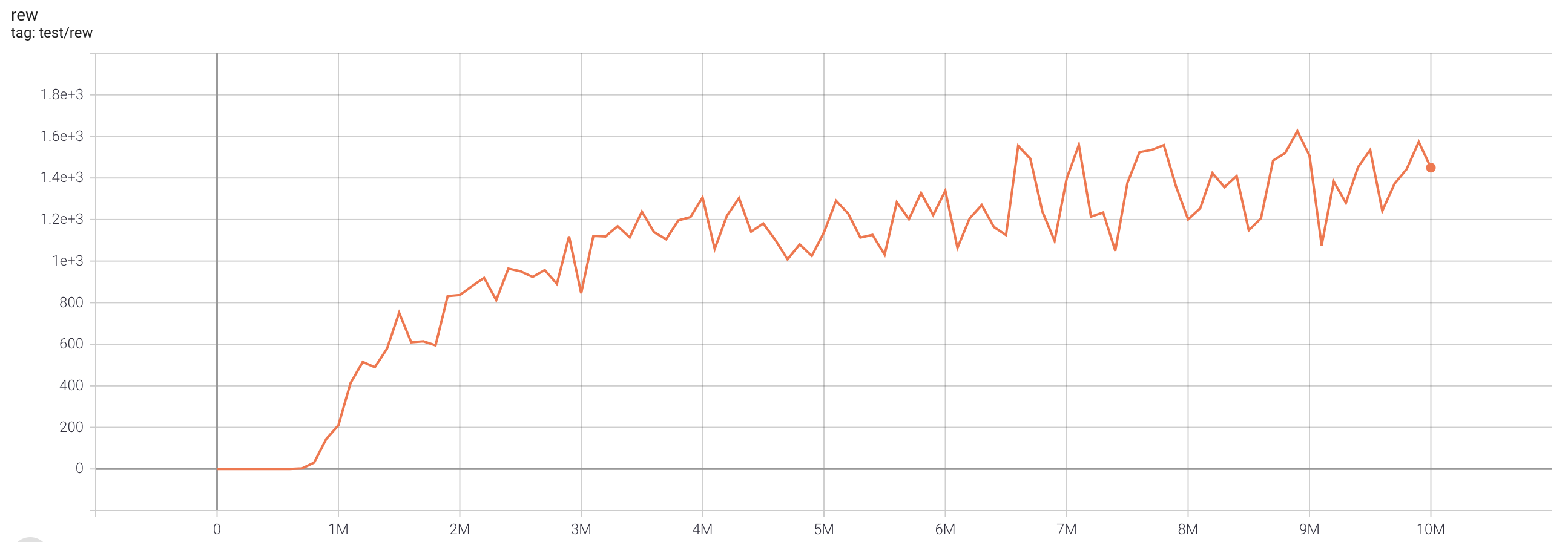 |
python3 atari_rainbow.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 16192.5 |  |
python3 atari_rainbow.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3101 |  |
python3 atari_rainbow.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 2126 |  |
python3 atari_rainbow.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 1794.5 |  |
python3 atari_rainbow.py --task "SpaceInvadersNoFrameskip-v4" |
PPO (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.2 |  |
python3 atari_ppo.py --task "PongNoFrameskip-v4" |
| BreakoutNoFrameskip-v4 | 441.8 |  |
python3 atari_ppo.py --task "BreakoutNoFrameskip-v4" |
| EnduroNoFrameskip-v4 | 1245.4 |  |
python3 atari_ppo.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 17395 |  |
python3 atari_ppo.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2098 | 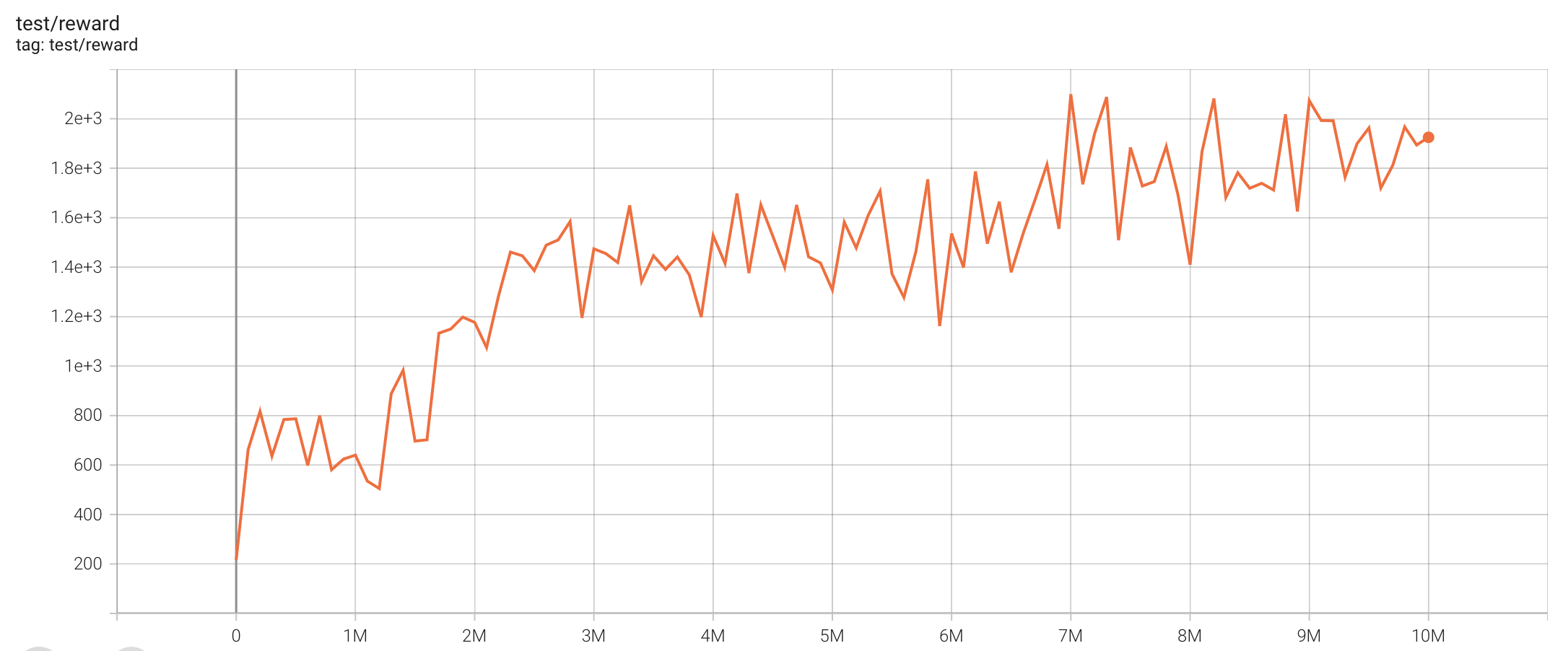 |
python3 atari_ppo.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 882 | 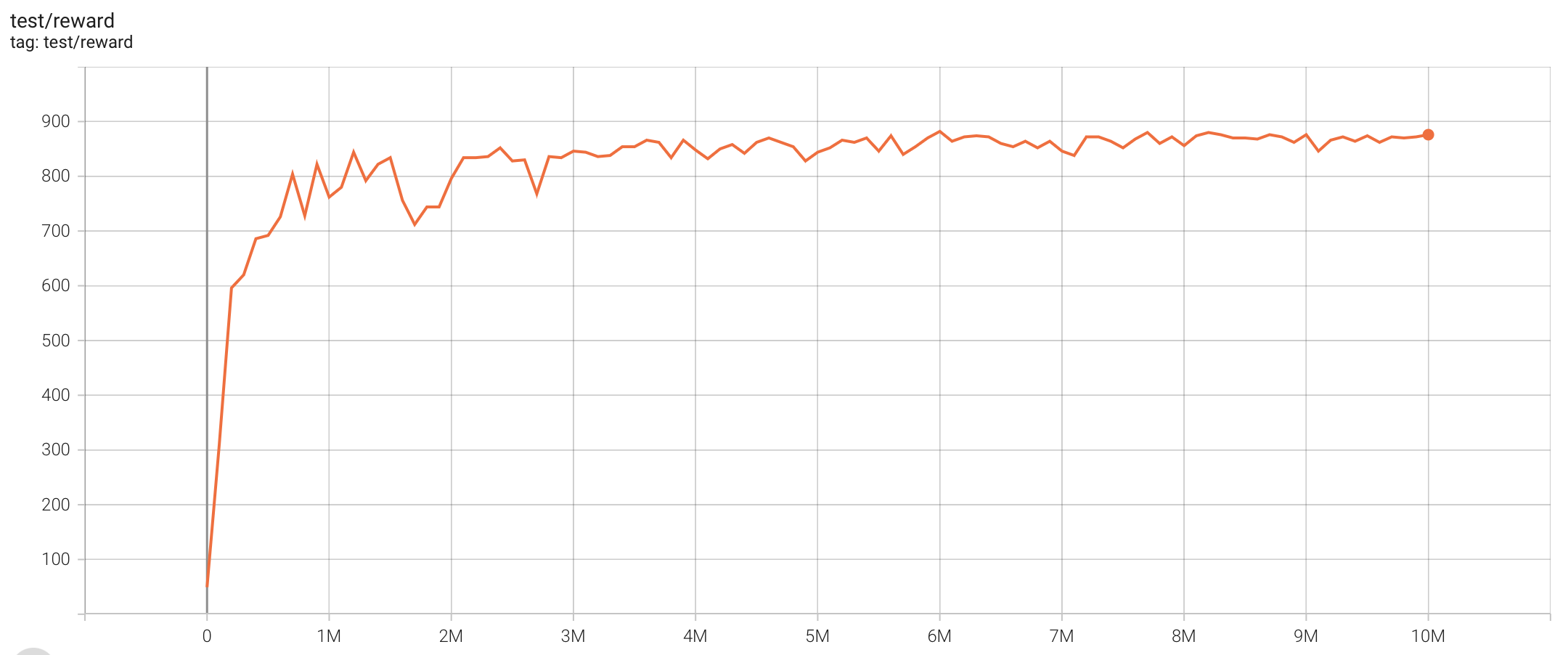 |
python3 atari_ppo.py --task "SeaquestNoFrameskip-v4" --lr 1e-4 |
| SpaceInvadersNoFrameskip-v4 | 1340.5 |  |
python3 atari_ppo.py --task "SpaceInvadersNoFrameskip-v4" |
SAC (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.1 |  |
python3 atari_sac.py --task "PongNoFrameskip-v4" |
| BreakoutNoFrameskip-v4 | 211.2 |  |
python3 atari_sac.py --task "BreakoutNoFrameskip-v4" --n-step 1 --actor-lr 1e-4 --critic-lr 1e-4 |
| EnduroNoFrameskip-v4 | 1290.7 | 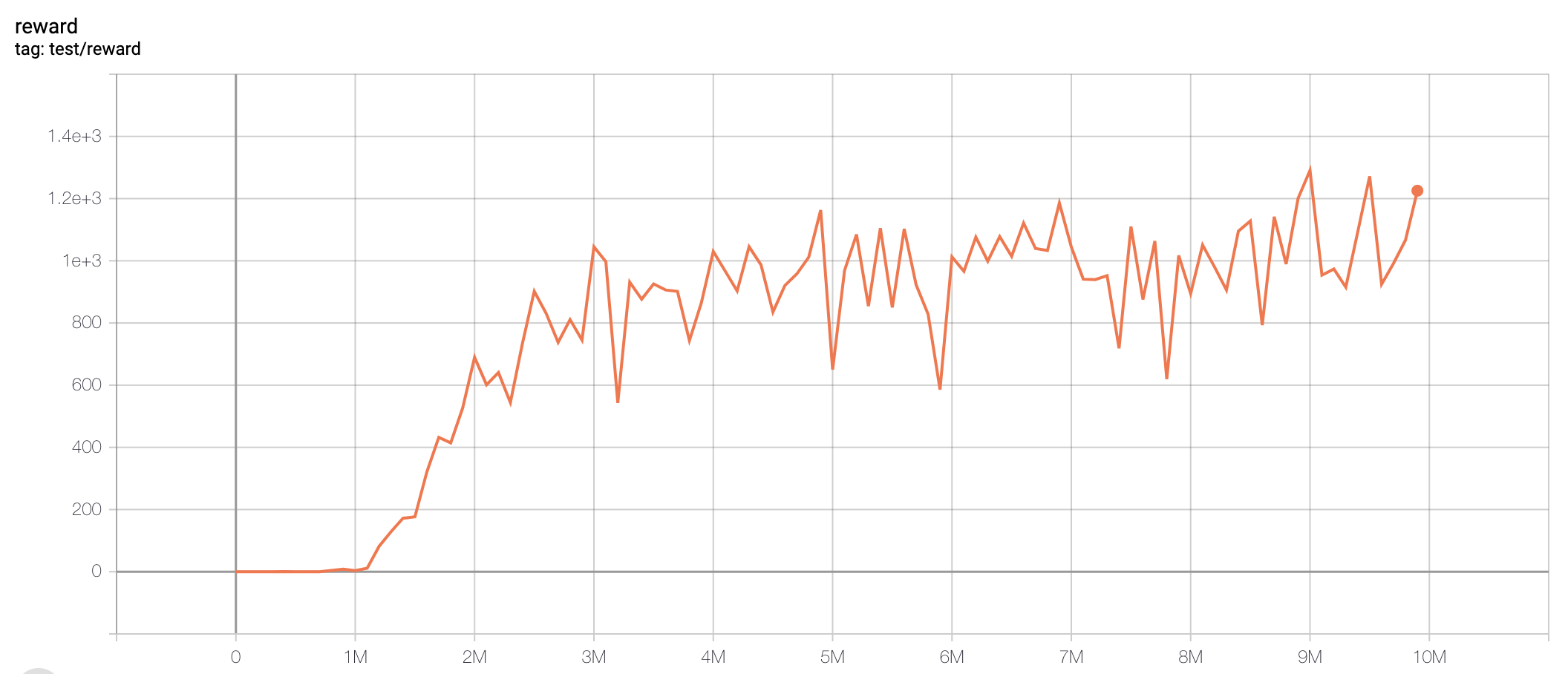 |
python3 atari_sac.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 13157.5 |  |
python3 atari_sac.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3836 |  |
python3 atari_sac.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 1772 |  |
python3 atari_sac.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 649 | 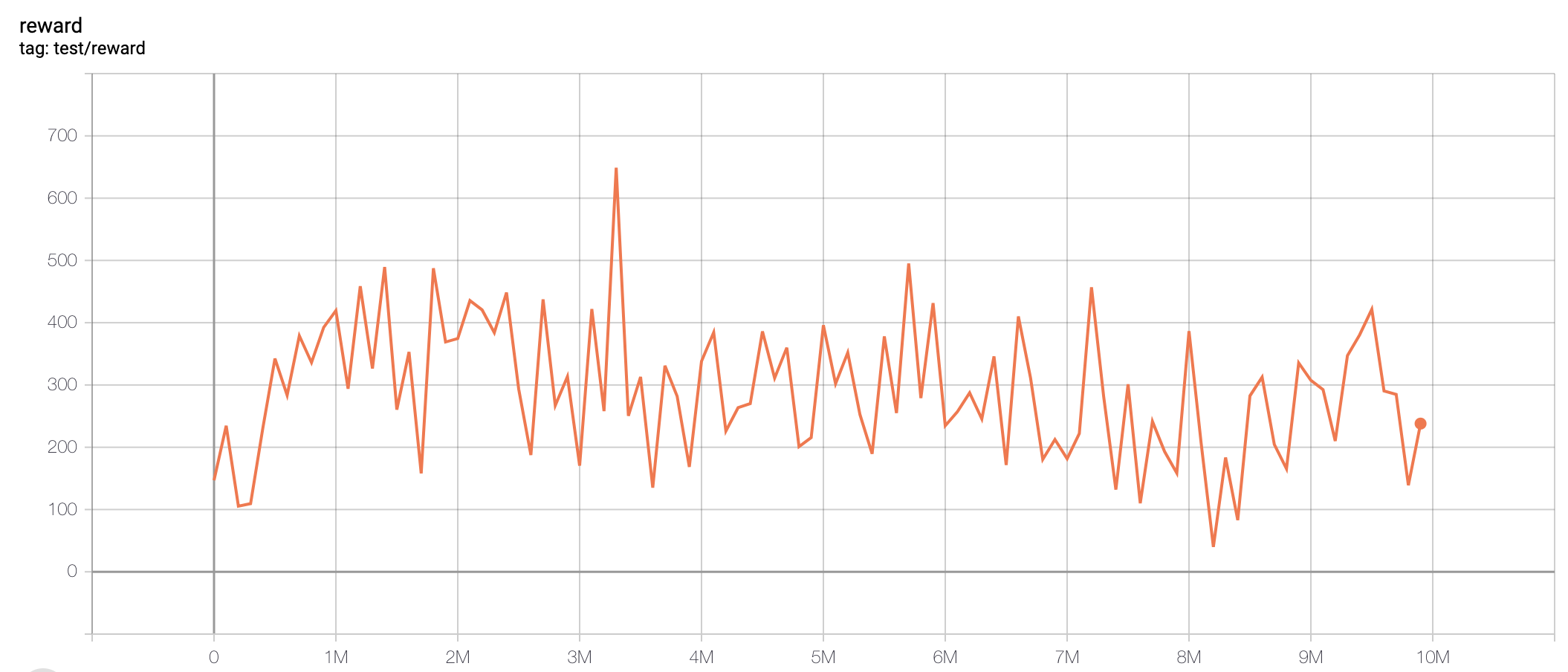 |
python3 atari_sac.py --task "SpaceInvadersNoFrameskip-v4" |