Closes #947 This removes all kwargs from all policy constructors. While doing that, I also improved several names and added a whole lot of TODOs. ## Functional changes: 1. Added possibility to pass None as `critic2` and `critic2_optim`. In fact, the default behavior then should cover the absolute majority of cases 2. Added a function called `clone_optimizer` as a temporary measure to support passing `critic2_optim=None` ## Breaking changes: 1. `action_space` is no longer optional. In fact, it already was non-optional, as there was a ValueError in BasePolicy.init. So now several examples were fixed to reflect that 2. `reward_normalization` removed from DDPG and children. It was never allowed to pass it as `True` there, an error would have been raised in `compute_n_step_reward`. Now I removed it from the interface 3. renamed `critic1` and similar to `critic`, in order to have uniform interfaces. Note that the `critic` in DDPG was optional for the sole reason that child classes used `critic1`. I removed this optionality (DDPG can't do anything with `critic=None`) 4. Several renamings of fields (mostly private to public, so backwards compatible) ## Additional changes: 1. Removed type and default declaration from docstring. This kind of duplication is really not necessary 2. Policy constructors are now only called using named arguments, not a fragile mixture of positional and named as before 5. Minor beautifications in typing and code 6. Generally shortened docstrings and made them uniform across all policies (hopefully) ## Comment: With these changes, several problems in tianshou's inheritance hierarchy become more apparent. I tried highlighting them for future work. --------- Co-authored-by: Dominik Jain <d.jain@appliedai.de>
Atari Environment
EnvPool
We highly recommend using envpool to run the following experiments. To install, in a linux machine, type:
pip install envpool
After that, atari_wrapper will automatically switch to envpool's Atari env. EnvPool's implementation is much faster (about 2~3x faster for pure execution speed, 1.5x for overall RL training pipeline) than python vectorized env implementation, and it's behavior is consistent to that approach (OpenAI wrapper), which will describe below.
For more information, please refer to EnvPool's GitHub, Docs, and 3rd-party report.
ALE-py
The sample speed is ~3000 env step per second (~12000 Atari frame per second in fact since we use frame_stack=4) under the normal mode (use a CNN policy and a collector, also storing data into the buffer).
The env wrapper is a crucial thing. Without wrappers, the agent cannot perform well enough on Atari games. Many existing RL codebases use OpenAI wrapper, but it is not the original DeepMind version (related issue). Dopamine has a different wrapper but unfortunately it cannot work very well in our codebase.
DQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters | time cost |
|---|---|---|---|---|
| PongNoFrameskip-v4 | 20 |  |
python3 atari_dqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
~30 min (~15 epoch) |
| BreakoutNoFrameskip-v4 | 316 |  |
python3 atari_dqn.py --task "BreakoutNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| EnduroNoFrameskip-v4 | 670 |  |
python3 atari_dqn.py --task "EnduroNoFrameskip-v4 " --test-num 100 |
3~4h (100 epoch) |
| QbertNoFrameskip-v4 | 7307 |  |
python3 atari_dqn.py --task "QbertNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| MsPacmanNoFrameskip-v4 | 2107 |  |
python3 atari_dqn.py --task "MsPacmanNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| SeaquestNoFrameskip-v4 | 2088 |  |
python3 atari_dqn.py --task "SeaquestNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| SpaceInvadersNoFrameskip-v4 | 812.2 |  |
python3 atari_dqn.py --task "SpaceInvadersNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
Note: The eps_train_final and eps_test in the original DQN paper is 0.1 and 0.01, but some works found that smaller eps helps improve the performance. Also, a large batchsize (say 64 instead of 32) will help faster convergence but will slow down the training speed.
We haven't tuned this result to the best, so have fun with playing these hyperparameters!
C51 (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20 |  |
python3 atari_c51.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 536.6 |  |
python3 atari_c51.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1032 |  |
python3 atari_c51.py --task "EnduroNoFrameskip-v4 " |
| QbertNoFrameskip-v4 | 16245 |  |
python3 atari_c51.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3133 |  |
python3 atari_c51.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 6226 |  |
python3 atari_c51.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 988.5 |  |
python3 atari_c51.py --task "SpaceInvadersNoFrameskip-v4" |
Note: The selection of n_step is based on Figure 6 in the Rainbow paper.
QRDQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20 |  |
python3 atari_qrdqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 409.2 |  |
python3 atari_qrdqn.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1055.9 |  |
python3 atari_qrdqn.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 14990 |  |
python3 atari_qrdqn.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2886 |  |
python3 atari_qrdqn.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 5676 |  |
python3 atari_qrdqn.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 938 |  |
python3 atari_qrdqn.py --task "SpaceInvadersNoFrameskip-v4" |
IQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.3 |  |
python3 atari_iqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 496.7 |  |
python3 atari_iqn.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1545 |  |
python3 atari_iqn.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 15342.5 |  |
python3 atari_iqn.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2915 | 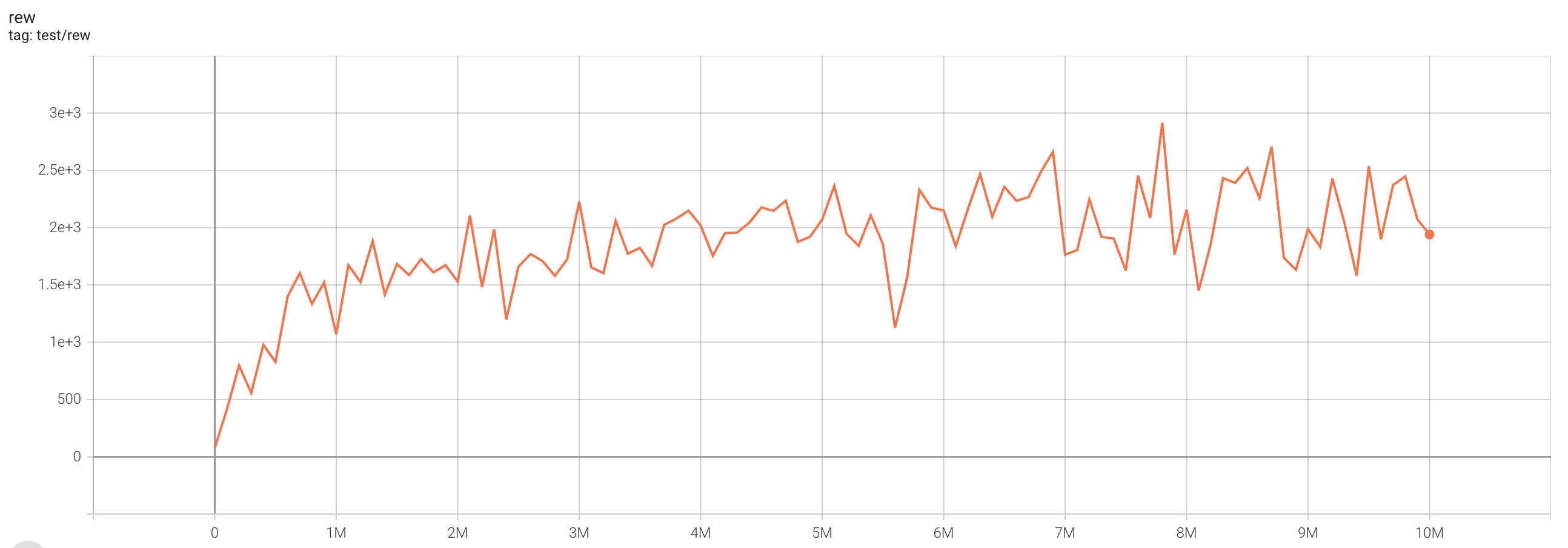 |
python3 atari_iqn.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 4874 |  |
python3 atari_iqn.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 1498.5 |  |
python3 atari_iqn.py --task "SpaceInvadersNoFrameskip-v4" |
FQF (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.7 |  |
python3 atari_fqf.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 517.3 |  |
python3 atari_fqf.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 2240.5 |  |
python3 atari_fqf.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 16172.5 |  |
python3 atari_fqf.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2429 |  |
python3 atari_fqf.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 10775 | 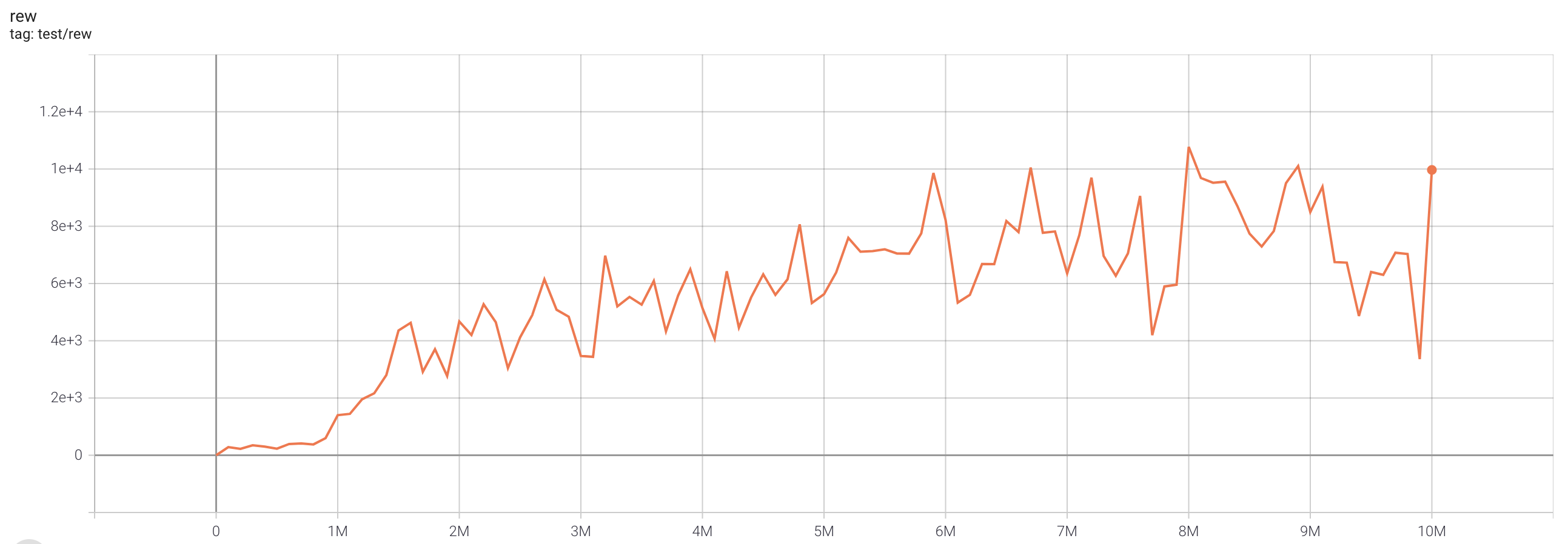 |
python3 atari_fqf.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 2482 |  |
python3 atari_fqf.py --task "SpaceInvadersNoFrameskip-v4" |
Rainbow (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 21 |  |
python3 atari_rainbow.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 684.6 |  |
python3 atari_rainbow.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1625.9 |  |
python3 atari_rainbow.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 16192.5 |  |
python3 atari_rainbow.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3101 |  |
python3 atari_rainbow.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 2126 |  |
python3 atari_rainbow.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 1794.5 |  |
python3 atari_rainbow.py --task "SpaceInvadersNoFrameskip-v4" |
PPO (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.2 |  |
python3 atari_ppo.py --task "PongNoFrameskip-v4" |
| BreakoutNoFrameskip-v4 | 441.8 |  |
python3 atari_ppo.py --task "BreakoutNoFrameskip-v4" |
| EnduroNoFrameskip-v4 | 1245.4 |  |
python3 atari_ppo.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 17395 |  |
python3 atari_ppo.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2098 |  |
python3 atari_ppo.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 882 |  |
python3 atari_ppo.py --task "SeaquestNoFrameskip-v4" --lr 1e-4 |
| SpaceInvadersNoFrameskip-v4 | 1340.5 |  |
python3 atari_ppo.py --task "SpaceInvadersNoFrameskip-v4" |
SAC (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.1 |  |
python3 atari_sac.py --task "PongNoFrameskip-v4" |
| BreakoutNoFrameskip-v4 | 211.2 |  |
python3 atari_sac.py --task "BreakoutNoFrameskip-v4" --n-step 1 --actor-lr 1e-4 --critic-lr 1e-4 |
| EnduroNoFrameskip-v4 | 1290.7 |  |
python3 atari_sac.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 13157.5 | 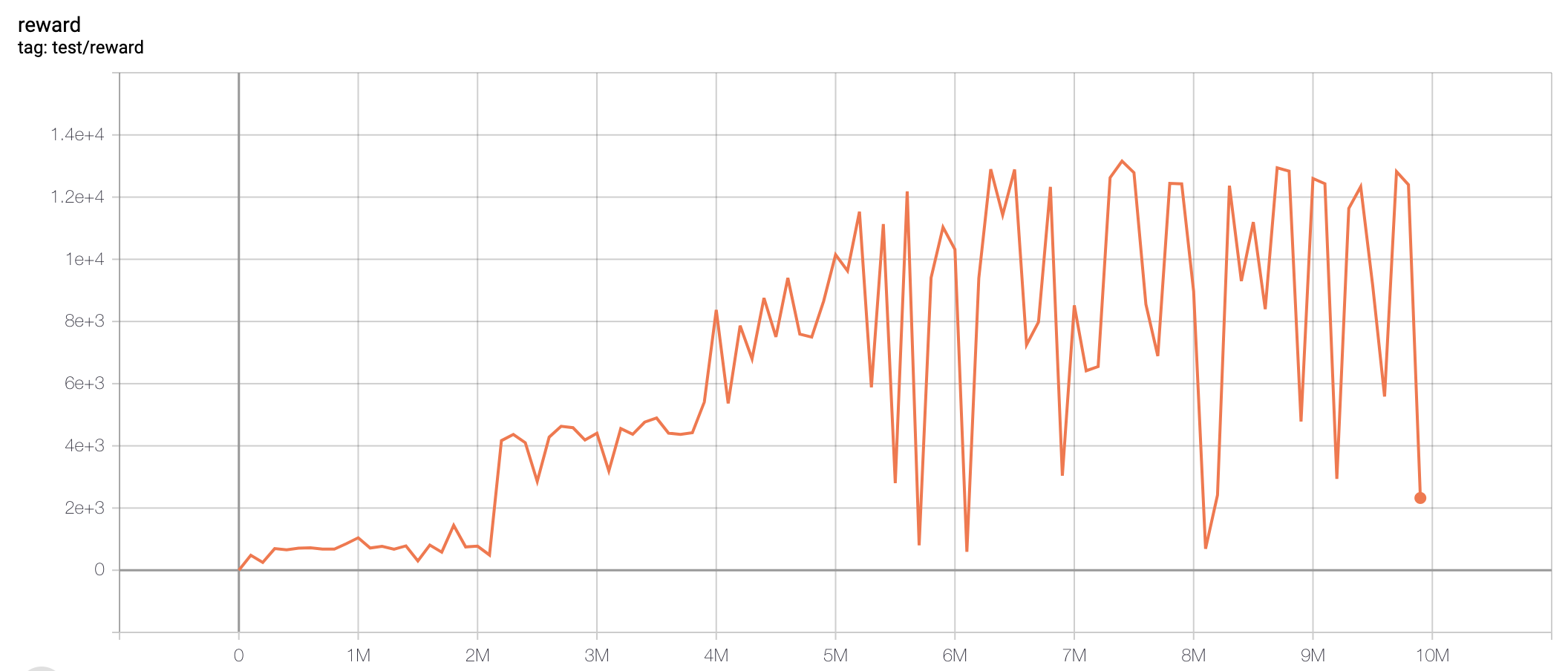 |
python3 atari_sac.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3836 |  |
python3 atari_sac.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 1772 |  |
python3 atari_sac.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 649 |  |
python3 atari_sac.py --task "SpaceInvadersNoFrameskip-v4" |