This PR adds strict typing to the output of `update` and `learn` in all
policies. This will likely be the last large refactoring PR before the
next release (0.6.0, not 1.0.0), so it requires some attention. Several
difficulties were encountered on the path to that goal:
1. The policy hierarchy is actually "broken" in the sense that the keys
of dicts that were output by `learn` did not follow the same enhancement
(inheritance) pattern as the policies. This is a real problem and should
be addressed in the near future. Generally, several aspects of the
policy design and hierarchy might deserve a dedicated discussion.
2. Each policy needs to be generic in the stats return type, because one
might want to extend it at some point and then also extend the stats.
Even within the source code base this pattern is necessary in many
places.
3. The interaction between learn and update is a bit quirky, we
currently handle it by having update modify special field inside
TrainingStats, whereas all other fields are handled by learn.
4. The IQM module is a policy wrapper and required a
TrainingStatsWrapper. The latter relies on a bunch of black magic.
They were addressed by:
1. Live with the broken hierarchy, which is now made visible by bounds
in generics. We use type: ignore where appropriate.
2. Make all policies generic with bounds following the policy
inheritance hierarchy (which is incorrect, see above). We experimented a
bit with nested TrainingStats classes, but that seemed to add more
complexity and be harder to understand. Unfortunately, mypy thinks that
the code below is wrong, wherefore we have to add `type: ignore` to the
return of each `learn`
```python
T = TypeVar("T", bound=int)
def f() -> T:
return 3
```
3. See above
4. Write representative tests for the `TrainingStatsWrapper`. Still, the
black magic might cause nasty surprises down the line (I am not proud of
it)...
Closes #933
---------
Co-authored-by: Maximilian Huettenrauch <m.huettenrauch@appliedai.de>
Co-authored-by: Michael Panchenko <m.panchenko@appliedai.de>
Atari Environment
EnvPool
We highly recommend using envpool to run the following experiments. To install, in a linux machine, type:
pip install envpool
After that, atari_wrapper will automatically switch to envpool's Atari env. EnvPool's implementation is much faster (about 2~3x faster for pure execution speed, 1.5x for overall RL training pipeline) than python vectorized env implementation, and it's behavior is consistent to that approach (OpenAI wrapper), which will describe below.
For more information, please refer to EnvPool's GitHub, Docs, and 3rd-party report.
ALE-py
The sample speed is ~3000 env step per second (~12000 Atari frame per second in fact since we use frame_stack=4) under the normal mode (use a CNN policy and a collector, also storing data into the buffer).
The env wrapper is a crucial thing. Without wrappers, the agent cannot perform well enough on Atari games. Many existing RL codebases use OpenAI wrapper, but it is not the original DeepMind version (related issue). Dopamine has a different wrapper but unfortunately it cannot work very well in our codebase.
DQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters | time cost |
|---|---|---|---|---|
| PongNoFrameskip-v4 | 20 |  |
python3 atari_dqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
~30 min (~15 epoch) |
| BreakoutNoFrameskip-v4 | 316 |  |
python3 atari_dqn.py --task "BreakoutNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| EnduroNoFrameskip-v4 | 670 |  |
python3 atari_dqn.py --task "EnduroNoFrameskip-v4 " --test-num 100 |
3~4h (100 epoch) |
| QbertNoFrameskip-v4 | 7307 |  |
python3 atari_dqn.py --task "QbertNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| MsPacmanNoFrameskip-v4 | 2107 |  |
python3 atari_dqn.py --task "MsPacmanNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| SeaquestNoFrameskip-v4 | 2088 |  |
python3 atari_dqn.py --task "SeaquestNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| SpaceInvadersNoFrameskip-v4 | 812.2 |  |
python3 atari_dqn.py --task "SpaceInvadersNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
Note: The eps_train_final and eps_test in the original DQN paper is 0.1 and 0.01, but some works found that smaller eps helps improve the performance. Also, a large batchsize (say 64 instead of 32) will help faster convergence but will slow down the training speed.
We haven't tuned this result to the best, so have fun with playing these hyperparameters!
C51 (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20 | 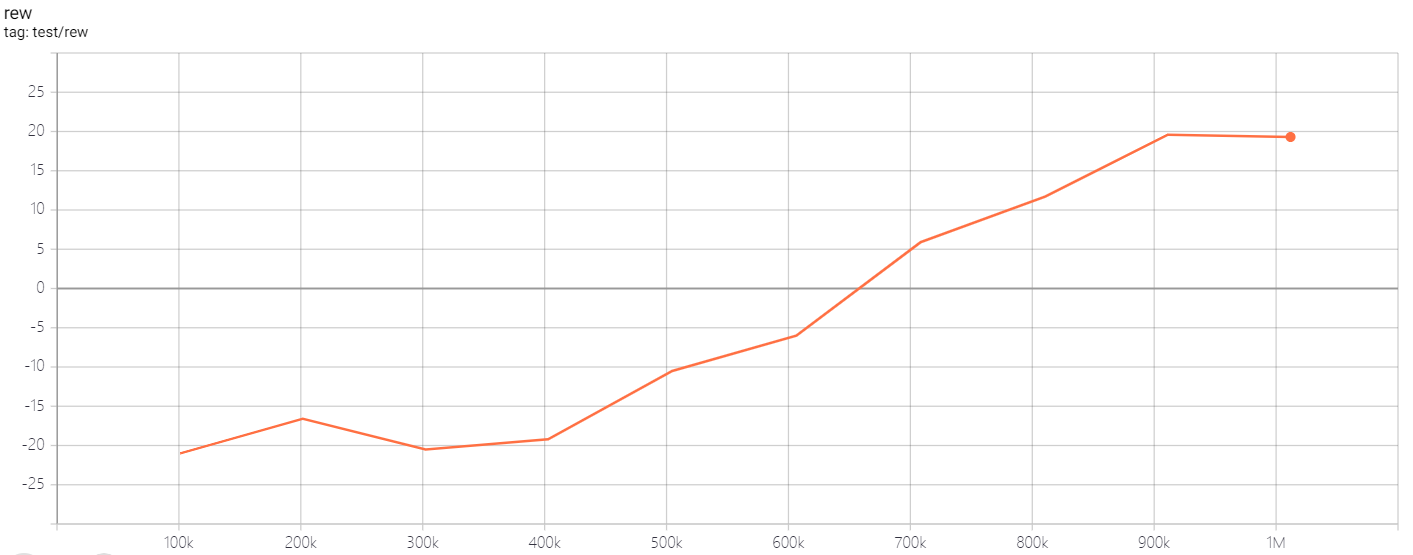 |
python3 atari_c51.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 536.6 |  |
python3 atari_c51.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1032 |  |
python3 atari_c51.py --task "EnduroNoFrameskip-v4 " |
| QbertNoFrameskip-v4 | 16245 |  |
python3 atari_c51.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3133 |  |
python3 atari_c51.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 6226 |  |
python3 atari_c51.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 988.5 |  |
python3 atari_c51.py --task "SpaceInvadersNoFrameskip-v4" |
Note: The selection of n_step is based on Figure 6 in the Rainbow paper.
QRDQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20 |  |
python3 atari_qrdqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 409.2 |  |
python3 atari_qrdqn.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1055.9 |  |
python3 atari_qrdqn.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 14990 |  |
python3 atari_qrdqn.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2886 |  |
python3 atari_qrdqn.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 5676 |  |
python3 atari_qrdqn.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 938 |  |
python3 atari_qrdqn.py --task "SpaceInvadersNoFrameskip-v4" |
IQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.3 |  |
python3 atari_iqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 496.7 |  |
python3 atari_iqn.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1545 |  |
python3 atari_iqn.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 15342.5 |  |
python3 atari_iqn.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2915 |  |
python3 atari_iqn.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 4874 |  |
python3 atari_iqn.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 1498.5 |  |
python3 atari_iqn.py --task "SpaceInvadersNoFrameskip-v4" |
FQF (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.7 |  |
python3 atari_fqf.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 517.3 |  |
python3 atari_fqf.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 2240.5 |  |
python3 atari_fqf.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 16172.5 |  |
python3 atari_fqf.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2429 |  |
python3 atari_fqf.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 10775 |  |
python3 atari_fqf.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 2482 |  |
python3 atari_fqf.py --task "SpaceInvadersNoFrameskip-v4" |
Rainbow (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 21 |  |
python3 atari_rainbow.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 684.6 |  |
python3 atari_rainbow.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1625.9 |  |
python3 atari_rainbow.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 16192.5 |  |
python3 atari_rainbow.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3101 |  |
python3 atari_rainbow.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 2126 |  |
python3 atari_rainbow.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 1794.5 |  |
python3 atari_rainbow.py --task "SpaceInvadersNoFrameskip-v4" |
PPO (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.2 |  |
python3 atari_ppo.py --task "PongNoFrameskip-v4" |
| BreakoutNoFrameskip-v4 | 441.8 |  |
python3 atari_ppo.py --task "BreakoutNoFrameskip-v4" |
| EnduroNoFrameskip-v4 | 1245.4 |  |
python3 atari_ppo.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 17395 |  |
python3 atari_ppo.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 2098 |  |
python3 atari_ppo.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 882 |  |
python3 atari_ppo.py --task "SeaquestNoFrameskip-v4" --lr 1e-4 |
| SpaceInvadersNoFrameskip-v4 | 1340.5 |  |
python3 atari_ppo.py --task "SpaceInvadersNoFrameskip-v4" |
SAC (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20.1 |  |
python3 atari_sac.py --task "PongNoFrameskip-v4" |
| BreakoutNoFrameskip-v4 | 211.2 |  |
python3 atari_sac.py --task "BreakoutNoFrameskip-v4" --n-step 1 --actor-lr 1e-4 --critic-lr 1e-4 |
| EnduroNoFrameskip-v4 | 1290.7 |  |
python3 atari_sac.py --task "EnduroNoFrameskip-v4" |
| QbertNoFrameskip-v4 | 13157.5 |  |
python3 atari_sac.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3836 |  |
python3 atari_sac.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 1772 |  |
python3 atari_sac.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 649 |  |
python3 atari_sac.py --task "SpaceInvadersNoFrameskip-v4" |