This PR focus on refactor of logging method to solve bug of nan reward and log interval. After these two pr, hopefully fundamental change of tianshou/data is finished. We then can concentrate on building benchmarks of tianshou finally. Things changed: 1. trainer now accepts logger (BasicLogger or LazyLogger) instead of writer; 2. remove utils.SummaryWriter;
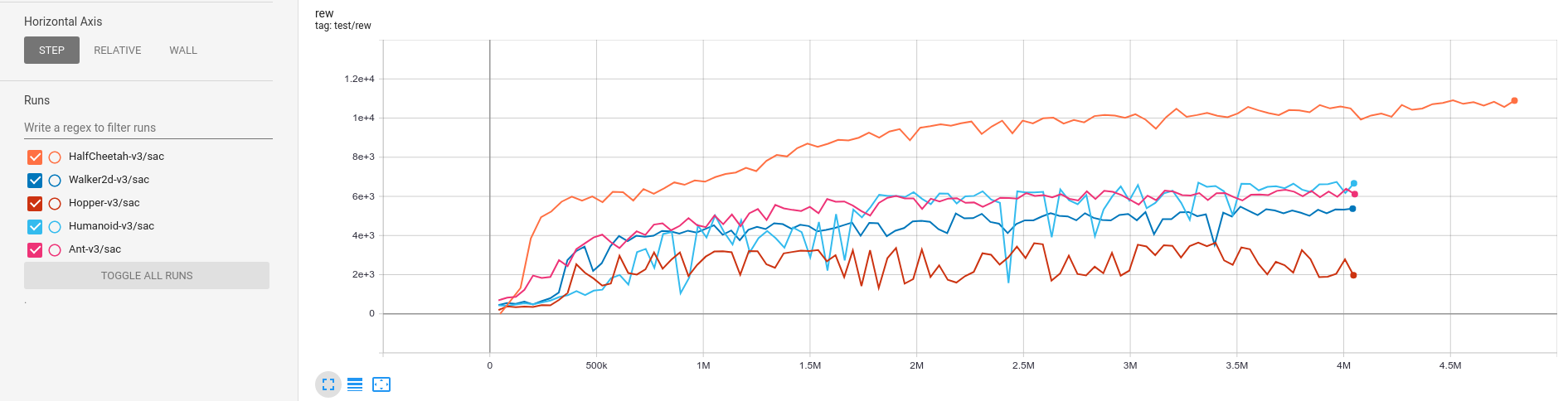
Mujoco Result
SAC (single run)
The best reward computes from 100 episodes returns in the test phase.
SAC on Swimmer-v3 always stops at 47~48.
| task | 3M best reward | parameters | time cost (3M) |
|---|---|---|---|
| HalfCheetah-v3 | 10157.70 ± 171.70 | python3 mujoco_sac.py --task HalfCheetah-v3 |
2~3h |
| Walker2d-v3 | 5143.04 ± 15.57 | python3 mujoco_sac.py --task Walker2d-v3 |
2~3h |
| Hopper-v3 | 3604.19 ± 169.55 | python3 mujoco_sac.py --task Hopper-v3 |
2~3h |
| Humanoid-v3 | 6579.20 ± 1470.57 | python3 mujoco_sac.py --task Humanoid-v3 --alpha 0.05 |
2~3h |
| Ant-v3 | 6281.65 ± 686.28 | python3 mujoco_sac.py --task Ant-v3 |
2~3h |
Which parts are important?
- DO NOT share the same network with two critic networks.
- The sigma (of the Gaussian policy) MUST be conditioned on input.
- The network size should not be less than 256.
- The deterministic evaluation helps a lot :)