This is the first commit of 6 commits mentioned in #274, which features 1. Refactor of `Class Net` to support any form of MLP. 2. Enable type check in utils.network. 3. Relative change in docs/test/examples. 4. Move atari-related network to examples/atari/atari_network.py Co-authored-by: Trinkle23897 <trinkle23897@gmail.com>
Atari General
The sample speed is ~3000 env step per second (~12000 Atari frame per second in fact since we use frame_stack=4) under the normal mode (use a CNN policy and a collector, also storing data into the buffer). The main bottleneck is training the convolutional neural network.
The Atari env seed cannot be fixed due to the discussion here, but it is not a big issue since on Atari it will always have the similar results.
The env wrapper is a crucial thing. Without wrappers, the agent cannot perform well enough on Atari games. Many existing RL codebases use OpenAI wrapper, but it is not the original DeepMind version (related issue). Dopamine has a different wrapper but unfortunately it cannot work very well in our codebase.
DQN (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters | time cost |
|---|---|---|---|---|
| PongNoFrameskip-v4 | 20 |  |
python3 atari_dqn.py --task "PongNoFrameskip-v4" --batch-size 64 |
~30 min (~15 epoch) |
| BreakoutNoFrameskip-v4 | 316 |  |
python3 atari_dqn.py --task "BreakoutNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| EnduroNoFrameskip-v4 | 670 |  |
python3 atari_dqn.py --task "EnduroNoFrameskip-v4 " --test-num 100 |
3~4h (100 epoch) |
| QbertNoFrameskip-v4 | 7307 |  |
python3 atari_dqn.py --task "QbertNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| MsPacmanNoFrameskip-v4 | 2107 | 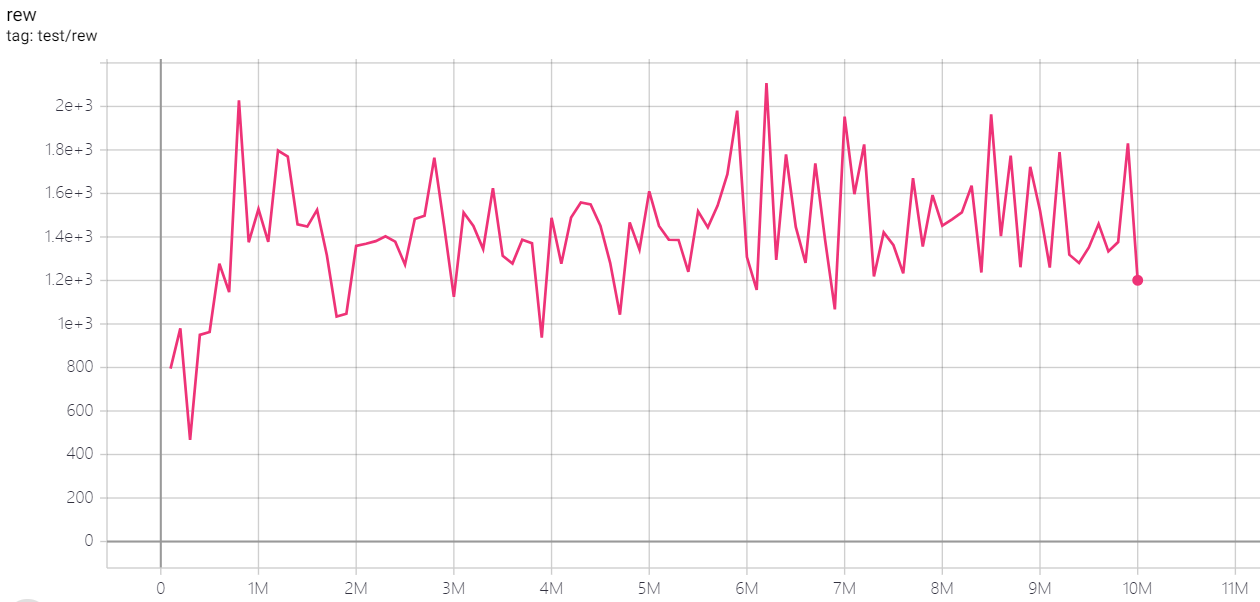 |
python3 atari_dqn.py --task "MsPacmanNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| SeaquestNoFrameskip-v4 | 2088 |  |
python3 atari_dqn.py --task "SeaquestNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
| SpaceInvadersNoFrameskip-v4 | 812.2 |  |
python3 atari_dqn.py --task "SpaceInvadersNoFrameskip-v4" --test-num 100 |
3~4h (100 epoch) |
Note: The eps_train_final and eps_test in the original DQN paper is 0.1 and 0.01, but some works found that smaller eps helps improve the performance. Also, a large batchsize (say 64 instead of 32) will help faster convergence but will slow down the training speed.
We haven't tuned this result to the best, so have fun with playing these hyperparameters!
C51 (single run)
One epoch here is equal to 100,000 env step, 100 epochs stand for 10M.
| task | best reward | reward curve | parameters |
|---|---|---|---|
| PongNoFrameskip-v4 | 20 |  |
python3 atari_c51.py --task "PongNoFrameskip-v4" --batch-size 64 |
| BreakoutNoFrameskip-v4 | 536.6 |  |
python3 atari_c51.py --task "BreakoutNoFrameskip-v4" --n-step 1 |
| EnduroNoFrameskip-v4 | 1032 |  |
python3 atari_c51.py --task "EnduroNoFrameskip-v4 " |
| QbertNoFrameskip-v4 | 16245 |  |
python3 atari_c51.py --task "QbertNoFrameskip-v4" |
| MsPacmanNoFrameskip-v4 | 3133 |  |
python3 atari_c51.py --task "MsPacmanNoFrameskip-v4" |
| SeaquestNoFrameskip-v4 | 6226 |  |
python3 atari_c51.py --task "SeaquestNoFrameskip-v4" |
| SpaceInvadersNoFrameskip-v4 | 988.5 |  |
python3 atari_c51.py --task "SpaceInvadersNoFrameskip-v4" |
Note: The selection of n_step is based on Figure 6 in the Rainbow paper.