Changes: - Disclaimer in README - Replaced all occurences of Gym with Gymnasium - Removed code that is now dead since we no longer need to support the old step API - Updated type hints to only allow new step API - Increased required version of envpool to support Gymnasium - Increased required version of PettingZoo to support Gymnasium - Updated `PettingZooEnv` to only use the new step API, removed hack to also support old API - I had to add some `# type: ignore` comments, due to new type hinting in Gymnasium. I'm not that familiar with type hinting but I believe that the issue is on the Gymnasium side and we are looking into it. - Had to update `MyTestEnv` to support `options` kwarg - Skip NNI tests because they still use OpenAI Gym - Also allow `PettingZooEnv` in vector environment - Updated doc page about ReplayBuffer to also talk about terminated and truncated flags. Still need to do: - Update the Jupyter notebooks in docs - Check the entire code base for more dead code (from compatibility stuff) - Check the reset functions of all environments/wrappers in code base to make sure they use the `options` kwarg - Someone might want to check test_env_finite.py - Is it okay to allow `PettingZooEnv` in vector environments? Might need to update docs?
Inverse Reinforcement Learning
In inverse reinforcement learning setting, the agent learns a policy from interaction with an environment without reward and a fixed dataset which is collected with an expert policy.
Continuous control
Once the dataset is collected, it will not be changed during training. We use d4rl datasets to train agent for continuous control. You can refer to d4rl to see how to use d4rl datasets.
We provide implementation of GAIL algorithm for continuous control.
Train
You can parse d4rl datasets into a ReplayBuffer , and set it as the parameter expert_buffer of GAILPolicy. irl_gail.py is an example of inverse RL using the d4rl dataset.
To train an agent with BCQ algorithm:
python irl_gail.py --task HalfCheetah-v2 --expert-data-task halfcheetah-expert-v2
GAIL (single run)
| task | best reward | reward curve | parameters |
|---|---|---|---|
| HalfCheetah-v2 | 5177.07 | 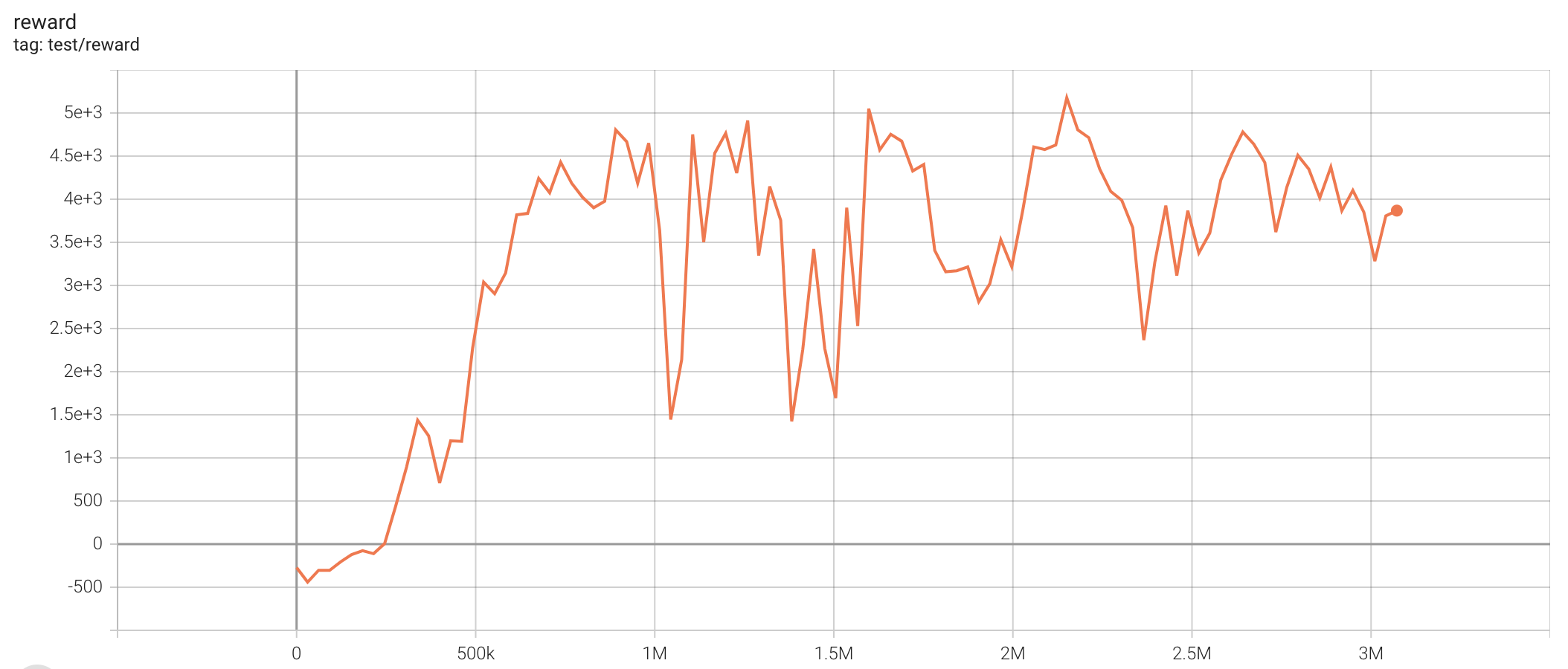 |
python3 irl_gail.py --task "HalfCheetah-v2" --expert-data-task "halfcheetah-expert-v2" |
| Hopper-v2 | 1761.44 | 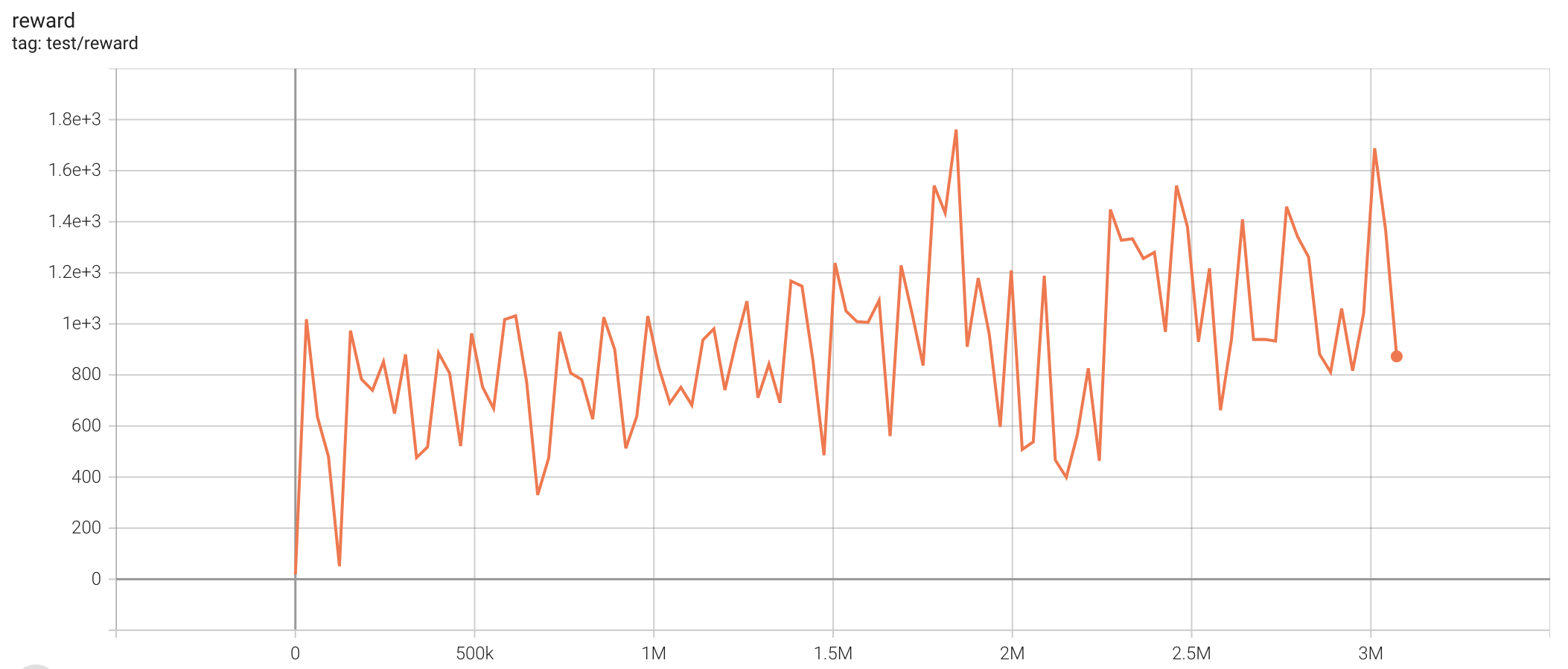 |
python3 irl_gail.py --task "Hopper-v2" --expert-data-task "hopper-expert-v2" |
| Walker2d-v2 | 2020.77 | 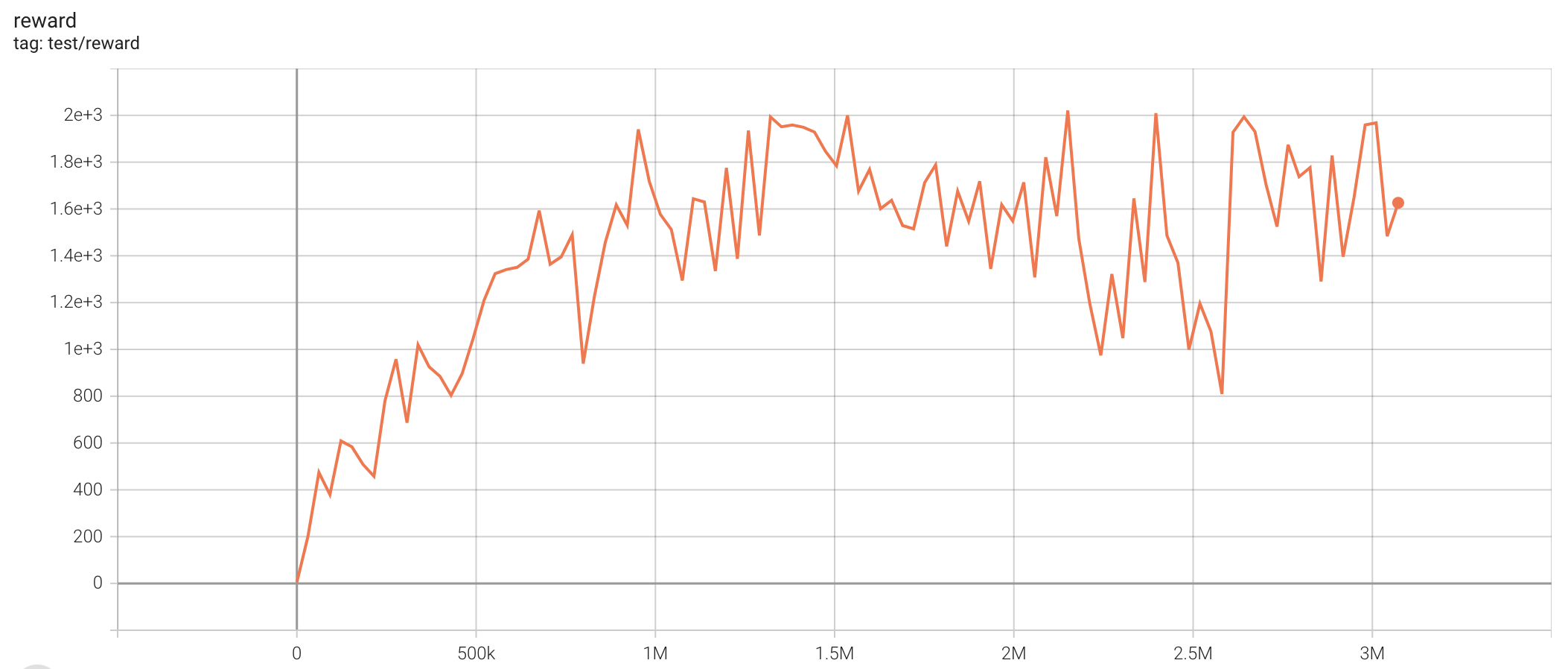 |
python3 irl_gail.py --task "Walker2d-v2" --expert-data-task "walker2d-expert-v2" |