This PR adds a new method for getting actions from an env's observation and info. This is useful for standard inference and stands in contrast to batch-based methods that are currently used in training and evaluation. Without this, users have to do some kind of gymnastics to actually perform inference with a trained policy. I have also added a test for the new method. In future PRs, this method should be included in the examples (in the the "watch" section). To add this required improving multiple typing things and, importantly, _simplifying the signature of `forward` in many policies!_ This is a **breaking change**, but it will likely affect no users. The `input` parameter of forward was a rather hacky mechanism, I believe it is good that it's gone now. It will also help with #948 . The main functional change is the addition of `compute_action` to `BasePolicy`. Other minor changes: - improvements in typing - updated PR and Issue templates - Improved handling of `max_action_num` Closes #981
ViZDoom
ViZDoom is a popular RL env for a famous first-person shooting game Doom. Here we provide some results and intuitions for this scenario.
EnvPool
We highly recommend using envpool to run the following experiments. To install, in a linux machine, type:
pip install envpool
After that, make_vizdoom_env will automatically switch to envpool's ViZDoom env. EnvPool's implementation is much faster (about 2~3x faster for pure execution speed, 1.5x for overall RL training pipeline) than python vectorized env implementation.
For more information, please refer to EnvPool's GitHub and Docs.
Train
To train an agent:
python3 vizdoom_c51.py --task {D1_basic|D2_navigation|D3_battle|D4_battle2}
D1 (health gathering) should finish training (no death) in less than 500k env step (5 epochs);
D3 can reach 1600+ reward (75+ killcount in 5 minutes);
D4 can reach 700+ reward. Here is the result:
(episode length, the maximum length is 2625 because we use frameskip=4, that is 10500/4=2625)

(episode reward)

To evaluate an agent's performance:
python3 vizdoom_c51.py --test-num 100 --resume-path policy.pth --watch --task {D1_basic|D3_battle|D4_battle2}
To save .lmp files for recording:
python3 vizdoom_c51.py --save-lmp --test-num 100 --resume-path policy.pth --watch --task {D1_basic|D3_battle|D4_battle2}
it will store lmp file in lmps/ directory. To watch these lmp files (for example, d3 lmp):
python3 replay.py maps/D3_battle.cfg episode_8_25.lmp
We provide two lmp files (d3 best and d4 best) under results/c51, you can use the following command to enjoy:
python3 replay.py maps/D3_battle.cfg results/c51/d3.lmp
python3 replay.py maps/D4_battle2.cfg results/c51/d4.lmp
Maps
See maps/README.md
Reward
- living reward is bad
- combo-action is really important
- negative reward for health and ammo2 is really helpful for d3/d4
- only with positive reward for health is really helpful for d1
- remove MOVE_BACKWARD may converge faster but the final performance may be lower
Algorithms
The setting is exactly the same as Atari. You can definitely try more algorithms listed in Atari example.
C51 (single run)
| task | best reward | reward curve | parameters |
|---|---|---|---|
| D2_navigation | 747.52 |  |
python3 vizdoom_c51.py --task "D2_navigation" |
| D3_battle | 1855.29 |  |
python3 vizdoom_c51.py --task "D3_battle" |
PPO (single run)
| task | best reward | reward curve | parameters |
|---|---|---|---|
| D2_navigation | 770.75 |  |
python3 vizdoom_ppo.py --task "D2_navigation" |
| D3_battle | 320.59 |  |
python3 vizdoom_ppo.py --task "D3_battle" |
PPO with ICM (single run)
| task | best reward | reward curve | parameters |
|---|---|---|---|
| D2_navigation | 844.99 |  |
python3 vizdoom_ppo.py --task "D2_navigation" --icm-lr-scale 10 |
| D3_battle | 547.08 | 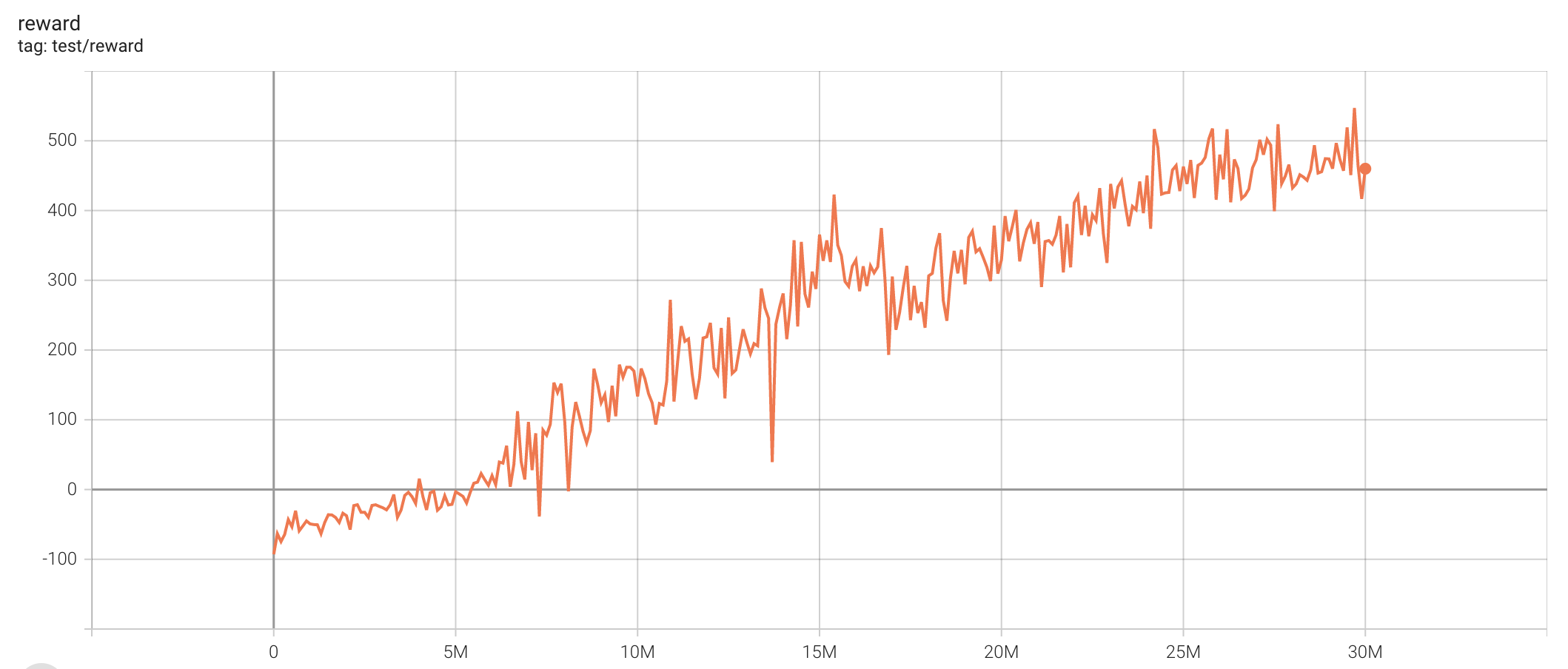 |
python3 vizdoom_ppo.py --task "D3_battle" --icm-lr-scale 10 |